TLDR: Neste post discutimos formas de acelerar o processo de criação de overviews, e no fim usamos um script que reduz o tempo de processamento em 20%-50%. O script é apresentado abaixo e está no github.
Na visualização de rasters é obrigatório construir as overviews ou pirâmides, para conseguirmos uma visualização rápida.
As overviews são uma série de cópias do nosso raster com resoluções cada vez menores (pixeis maiores), e geralmente cada nível aplica uma redução de 50% na resolução. Por exemplo, numa resolução original de 0,30m/pixel, as overviews são imagens com resoluções de 0,60 – 1,20 – 2,40m/pixel e assim sucessivamente até que não faz sentido reduzir mais a imagem.
Em geral, a construção destas pirâmides é feito com o comando gdaladdo, e é o processo mais moroso quando processamos grandes áreas. Nem a conversão com compressão, nem a união de muitos rasters leva tanto tempo.
Actualmente, com discos SSD rapidíssimos e memória super-abundante, e processadores multi-core, o comando gdaladdo que constrói overviews continua a usar apenas 1 core… por outro lado, é mais lento que outros comandos, como o gdal_translate.
Recentemente processei novos mosaicos para o Alentejo, desta vez com ortofotomapas com 0,30m de resolução, rgb+nir. E, claro, construir overviews foi uma tortura… mais de 8h para cada metade (dividi a área em 2 blocos este/oeste). O processador nunca passou dos 17% (i7 de 4 cores/8threads), e o disco SSD nunca passou de uns miseráveis 5MB/s (quando o disco é capaz de 1000MB/s). Muito frustrante…
O processo que uso consiste sempre em manter os ficheiros independentes, e criar um mosaico .vrt. Por hábito não crio mosaicos tif enormes. Este processo é descrito em artigos anteriores.
Depois de pesquisar online, vi 3 sugestões para melhorar o tempo de criar overviews:
- Criar uma escada de vrt’s e construir um nível de overviews diferente para cada um em paralelo usando o gdal_translate, e depois configurá-los para que o 1º referencie o 2º, e este o 3º, e por ai fora. Mais info aqui: http://osgeo-org.1560.x6.nabble.com/gdal-dev-Scale-dependent-VRT-for-overviews-td4966814.html.
- Ter 2 cópias iguais do vrt, construir níveis diferentes de overviews para cada vrt com 2 comandos simultâneos, e depois juntá-los num só overview usando o comando tiffcp!! Mais info aqui: https://gis.stackexchange.com/questions/281890/how-to-add-other-images-as-tiff-overviews.
- Criar imagens de resolução reduzida, usando o gdal_translate, e renomear estas imagens com extensão .ovr repetida, ou seja, mosaico.vrt.ovr, depois mosaico.vrt.ovr.ovr, e sucessivamente. Embora com ficheiros a mais, pareceu-me muito rápido.
Isto ensinou-me uma série de coisas novas:
- Os ficheiros .ovr são na verdade ficheiros TIFF multi-página (herança do tempo dos faxes!), onde um tiff é “colado” a outro dentro do mesmo ficheiro. Eu não sabia isto sobre os .ovr. Ou seja, cada resolução é um tiff, dentro do ovr, que é também um tiff (matrioska?).
- É possível juntar vários tiff num só tiff multi-página usando o comando “tiffcp tiff1 tiff2 tiffunido”.
- O OSGEO4W inclui uma versão “geo-activada” dos comandos tiff, mantendo as características SIG dos ficheiros.
- Podemos ter overviews de overviews, juntando a extensão .ovr ao ficheiro .ovr anterior, numa sucessão que funciona em gdal, qgis, e arcgis. Deve funcionar nos restantes programas, como geoserver, mapserver, etc.
Teste
Vamos fazer um teste com uma série mais pequena de ortofotomapas, para vermos qual é a melhoria no tempo de criação de overviews: vamos usar 3 processos simultânos de gdal_translate, onde cada processo constrói um resample diferente (x2, x4, x8), e renomeando-os para terem extensão .ovr acrescida.
A nossa coleção de ortos de testes é constituída por:
- 29 ficheiros 3 bandas x 8 bit, num total de 276MB, já comprimidos em tiff/jpeg, com 5km de lado, e 0,30m de resolução.
- Um mosaico virtual .vrt com todos os 29 ortos, “teste_script.vrt”, com dimensão de 166.667 x 100.000 pixeis.
O método consiste em executar 3 comandos em simultâneo:
- Processo 1: resample para 0,6m/pixel
- Processo 2: resample para 1,2m/pixel
- Processo 3: resample para 2,4m/pixel, mais construção de pirâmides para este resample apenas
Assim, no processo 1 teremos este comando:
gdal_translate -of gtiff -tr 0.6 0.6 -ro -r average --config GDAL_CACHEMAX 1024 -co photometric=ycbcr -co interleave=pixel -co tiled=yes -co compress=jpeg teste_script.vrt teste_script.vrt.ovr
Ou seja, construimos uma cópia do mosaico, em formato tiff, com 2x o tamanho do pixel original (0,6m/pixel) e damos o nome certo para que seja automaticamente reconhecido como overviews do original -> teste_script.vrt.ovr.
No processo 2, construímos um resample com 4x o tamanho do pixel (1,2m/pixel), e damos o nome que o faz ser reconhecido como overviews do 1º processo:
gdal_translate -of gtiff -tr 1.2 1.2 -ro -r average --config GDAL_CACHEMAX 1024 -co photometric=ycbcr -co interleave=pixel -co tiled=yes -co compress=jpeg teste_script.vrt teste_script.vrt.ovr.ovr
No processo 3, construímos o 3º nível, com 8x a resolução (2,4m/pixel), e com um nome que o marque como as overviews do 2º nível:
gdal_translate -of gtiff -tr 2.4 2.4 -ro -r average --config GDAL_CACHEMAX 1024 -co photometric=ycbcr -co interleave=pixel -co tiled=yes -co compress=jpeg teste_script.vrt teste_script.vrt.ovr.ovr.ovr
Já que sabemos que este resample é muitíssimo mais rápido que o 1º, terminando por isso muito cedo, podemos aproveitar para criar pirâmides para este 3º nível. Isto permitirá termos a série completa de overviews no final:
gdaladdo -ro -r average --config GDAL_CACHEMAX 1024 --config COMPRESS_OVERVIEW JPEG --config PHOTOMETRIC_OVERVIEW YCBCR --config INTERLEAVE_OVERVIEW PIXEL teste_script.vrt.ovr.ovr.ovr
O script faz uma série de correções aos nomes dos ficheiros caso detecte uma máscara externa, que é o caso do nosso teste (ficheiro .msk). Ficamos assim com os seguintes ficheiros:
50 194 teste_script.vrt
12 434 020 teste_script.vrt.msk
6 003 920 teste_script.vrt.msk.ovr
1 525 126 teste_script.vrt.msk.ovr.ovr
395 087 teste_script.vrt.msk.ovr.ovr.ovr
267 858 teste_script.vrt.msk.ovr.ovr.ovr.ovr
466 889 237 teste_script.vrt.ovr
116 024 726 teste_script.vrt.ovr.ovr
32 529 152 teste_script.vrt.ovr.ovr.ovr
11 135 760 teste_script.vrt.ovr.ovr.ovr.ovr
10 File(s) 647 255 080 bytes
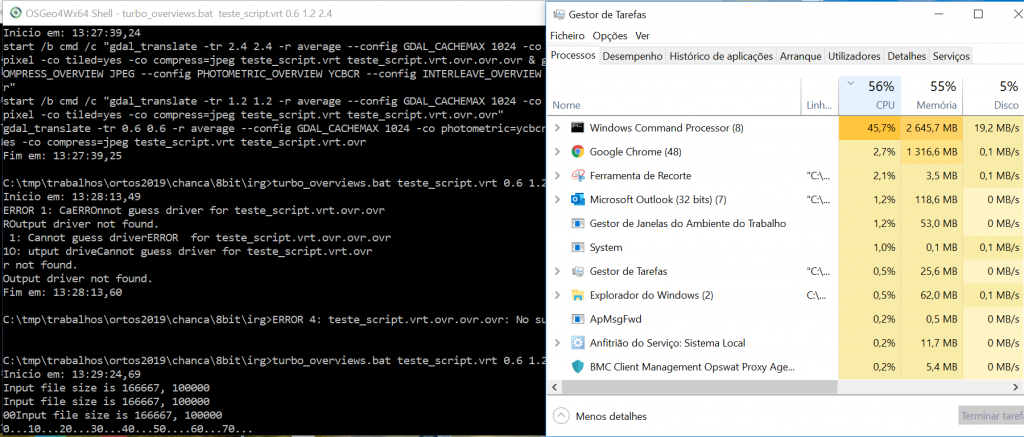
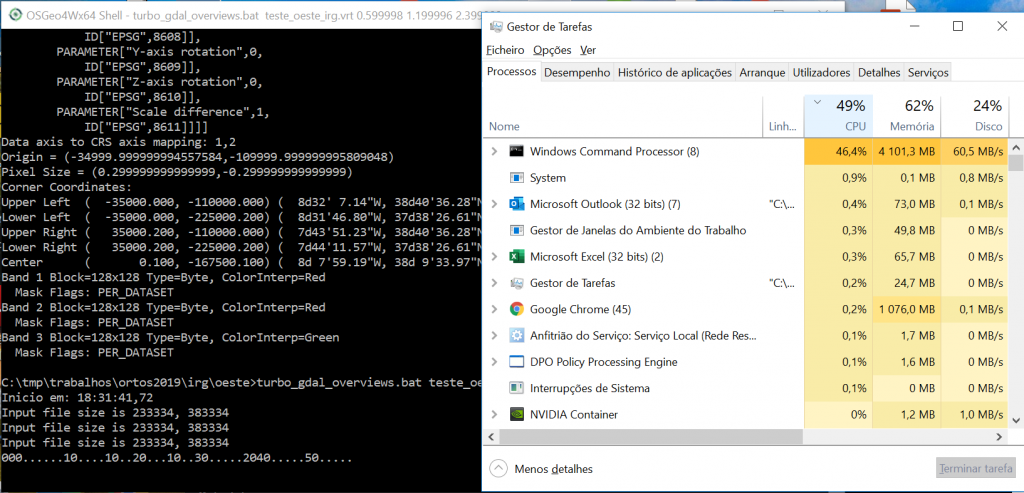
O tempo de execução foi de 06:47,4 min. E podemos ver a ocupação de CPU, disco e memória muito mais altos:
E funciona? Vamos a ver…
gdalinfo teste_script.vrt
Driver: VRT/Virtual Raster
Files: teste_script.vrt
teste_script.vrt.ovr
teste_script.vrt.ovr.ovr
teste_script.vrt.ovr.ovr.ovr
teste_script.vrt.ovr.ovr.ovr.ovr
teste_script.vrt.msk
230_060_irg.tif
230_065_irg.tif
... ... ... ... ...
Size is 166667, 100000
Coordinate System is:
... ... ... ... ...
Band 1 Block=128x128 Type=Byte, ColorInterp=Red
Min=0.000 Max=255.000
Minimum=0.000, Maximum=255.000, Mean=109.688, StdDev=100.399
Overviews: 83334x50000, 41667x25000, 20833x12500, 10417x6250, 5209x3125, 2605x1563, 1303x782, 652x391, 326x196, 163x98
Mask Flags: PER_DATASET
... ... ... ... ...
O gdalinfo reconhe todas as pirâmides. E o QGIS?
Pequeno à parte: Já em artigos anteriores referi que o QGIS tem de ser “convencido” a ler máscaras externas. Isto não causa problemas ao processo. Aparentemente, o GDAL tem um comportamento diferente com máscaras externas, em que as expõe com valores 0/1, em vez de valores 0/255 como acontece com máscaras internas. Sem esta correção a máscara não é detectadas correctamente pelo QGIS, e temos de a ignorar, aparecendo as zonas pretas sem dados. Se corrigirmos editando o vrt, tudo aparece correctamente. Mas em qualquer dos casos as overviews funcionam:
Com o gdaladdo “normal”
Para compararmos, vamos criar overviews com o processo normal:
timing "gdaladdo --config GDAL_CACHEMAX 1024 --config COMPRESS_OVERVIEW JPEG --config PHOTOMETRIC_OVERVIEW YCBCR --config INTERLEAVE_OVERVIEW PIXEL teste_gdaladdo.vrt"
14:52:45,10
a executar o comando indicado: "gdaladdo --config GDAL_CACHEMAX 1024 --config COMPRESS_OVERVIEW JPEG --config PHOTOMETRIC_OVERVIEW YCBCR --config INTERLEAVE_OVERVIEW PIXEL teste_gdaladdo.vrt"
0…10…20…30…40…50…60…70…80…90…100 - done.
0…10…20…30…40…50…60…70…80…90…100 - done.
15:01:17,19
Assim, o processo normal demorou 08:32,1 min.
E os ficheiros deste processo normal são:
50 194 teste_gdaladdo.vrt
23 195 175 teste_gdaladdo.vrt.msk
827 911 591 teste_gdaladdo.vrt.ovr
3 File(s) 851 156 960 bytes
Nota: este vrt tem uma máscara externa .msk. Como me esqueci do parâmetro -ro (readonly), as overviews da máscara foram adicionadas ao próprio msk. Também me esqueci do método resample average, que seria mais lento…
Comparação
O processo de construir overviews em paralelo, divido em 3 processos simultâneos, é 20% mais rápido, e ainda com um bónus de ocupar menos 23% em disco! (não sei porquê)
| Método | Tempo | Tamanho | Disco | CPU | RAM |
| gdaladdo normal | 08:32,1 | 850MB | 5MB/s | 15% | 1GB |
| gdal_translate x3 | 06:47,4 | 647 MB | 19MB/s | 45% | 3GB |
Ou seja, conseguimos subir o uso do CPU para 45%, e o disco para 19MB/s. Nada mau. A memória ocupada pelo processo depende do uso que fizermos da flag –config GDAL_CACHEMAX. No nosso caso, definimo-la como 1GB. Logo 3 processos ocupam obviamente 3x esta quantidade.
O ganho de velocidade resulta do processamento em simultâneo – enquanto se processa o 1º nível, processam-se logo os restantes e as máscaras também desses níveis caso exista máscara no raster original.
Script
Numa tentativa de automatizar o processo, criei um script bat para windows. Pode ser obtido aqui: https://github.com/dncpax/Turbo_GDAL_Overviews .
Algumas notas interessantes sobre o bat:
- É possível imitar uma execução em background usando “start /b” dentro do bat.
- A shell DOS só faz aritmética de inteiros, por isso temos de indicar as 3 resoluções que queremos – x2, x4 e x8 – porque em geral não são inteiros e não os conseguimos calcular no bat.
- Usamos DELAYEDEXPANSION porque precisamos de mostrar o tempo de execução.
- Temos de renomear os ficheiros resultantes da máscara externa (.msk) porque ficam com nomes que impedem o seu reconhecimento. O script trata disso com uma série de renames.
A migração para Linux deve ser fácil, porque 80% do script é só validação de argumentos. O que interessa são comandos gdal. Voluntários procuram-se…
Para executar indicamos o raster e as 3 resoluções iniciais das overviews:
turbo_overviews.bat teste_script.vrt 0.6 1.2 2.4 Inicio em: 13:29:24,69 Input file size is 166667, 100000 Input file size is 166667, 100000 00 Input file size is 166667, 100000 0…10…20…30…40…50….60…70…..80…..9010….100 - done. ..0…10…20…30….40…50…60…70…80…90.20..100 - done. 0…10…20…30…40…50…60…70…80…90….100 - done. 10..30…..40…20..50…..6030…..70…40.80…..90…50.100 - done. …60…70…80…90…100 - done. Fim em: 13:36:12,07
Conclusões
Se calhar este post é optimista: só fiz 1 teste sério… pode ser o caso de não funcionar mais vez nenhuma ;)…
Para mim é realmente estranho a falta de processamento multi-core no GDAL. Talvez seja uma questão de tempo, mas já se sente a falta. O que existe é muito incipiente e apenas funciona em cenários que não me são aplicáveis (e.g. compressão DEFLATE).
Há mais alternativas a este processo, mas nos testes que fiz não tive tão bons resultados.
Há outros programas que podem fazer resample de imagens e com processamento multi-core, como o imagemagick. Isto obrigará a copiar a georeferenciação para as imagens resultantes porque estes programas não reconhecem a componente SIG das imagens. Mas pode ser interessante.
De qualquer forma, por agora, este processo parece funcionar bem. Falta testar com um mosaico “à séria”. Pode ser que os 20% de maior rapidez se confirmem!
Até breve!
Adenda
Teste com um mosaico um pouco maior…
Este mosaico é similar mas maior: tem uma dimensão de 233.334 x 383.334 pixeis, em 258 ficheiros, num total de 10,3GB. Demorou 41:38,2 min, em vez de 01:35 h com o GDAL v.3.0.4 (na v2.3.0 tinha demorado 08:42:33 h) do gdaladdo… Ou seja, um ganho de 56%!
Observámos uma ocupação do disco interessante: mais de 60MB/s…
Os tamanhos foram similares: 4.4GB vs 4.9GB.
E correctamente visualizado em QGIS:
Neste mosaico mais encorpado, a melhoria é enorme… Curioso em ver a aplicação em mosaicos muito maiores.




Hi Duarte, very nice article! And is always good to learn something new.
Anyway I think that you may have possibly not considered a couple of important factors (of course you should test the following with your data, with the data we usually handle they make all the difference).
1) Windows is a inherently inferior OS when it comes to crunch data and squeeze the best out of your hardware. This is true with several GIS tools packages, R, and many more other software.
A quick proof (of course on the very same machine) using a small geotiff:
Windows:
timecmd gdaladdo 31754.tif -r nearest -ro 2 4 8 16 32 64
0…10…20…30…40…50…60…70…80…90…100 – done.
command took 0:0:0.36 (0.36s total)
GNU/Linux:
time gdaladdo 31754.tif -r nearest -ro 2 4 8 16 32 64
0…10…20…30…40…50…60…70…80…90…100 – done.
real 0m0,071s
user 0m0,063s
sys 0m0,008s
that is a quite better compared to Windows.
2) gdaladdo is single threaded, but this does not means you can take advantage of all (or most of the) cores of your system. We have a workstation dedicated to heavy geoprocessing and with Linux you can just simply do:
cat lista.csv | parallel -j X gdaladdo {} -r nearest -ro 2 4 8 16 32 64
where “lista.csv” is the list of your input files and “X” the number of cores you want to use (i.e. in our dual Xeon configuration we can do a nice -j 30 for example). That speeds up things “slightly” 😉 You can probably do something similar also on Windows, hopefully…
Gio, há quanto tempo!!! Desculpa a demora mas voltei a ser traído pela porcaria do sistema de email do wp e não fui notificado do teu comentário!!
Eu tenho alguns sistemas em ubuntu, e outros em windows, e não tenho (ainda) a mesma percepção da dif de desempenho… mas espero que seja mesmo assim, pq só terei a ganhar!
Quanto à paralelização do gdaladdo em vários comandos, o problema é que eu não crio ovr’s nos originais, mas sim no mosaico vrt que os agrega. Tenho pensado em ter ovr’s nos originais, e depois só níveis mais “altos” no mosaico vrt. Isto terá a vantagem de possibilitar a reconstrução parcial dos ovr’s no caso de um original ser substituído por uma nova versão (se houver uma correcção p.e.).
E assim já usar vários comandos gdaladdo como indicaste será possível.
A propósito, uma outra limitação com que ando às voltas é esta mesmo: reconstrução parcial de ovr’s existentes, para uma pequena área, em vez de ter de construir tudo de novo…
Hello world… teste de notificações…