O Docker tornou-se essencial hoje em dia… quase todos os produtos são distribuídos como containers e até muitas vezes nem há outra opção (os scripts de instalação começam a ser raros). O Docker Compose leva isto ainda mais longe, permitindo instalar e executar aplicações constituídas por múltiplos containers.
E qual é o problema com isto?
Bem, o problema é que quando um upgrade docker compose falha já numa fase avançada, por exemplo quando falham as migrações da base de dados, ficamos sem forma de voltar à versão anterior… se alguma coisa nos dados foi alterada pela nova versão, como fazemos para voltar à versão anterior que até funcionava tão bem!???
Este post discute o problema, fornece uma solução manual utilizando funcionalidades padrão do Docker, e apresenta uma solução mais avançada e automatizada para fazer backup de stacks Docker Compose. Aviso – este é o 1º artigo que escrevi com a ajuda do meu assistente pessoal virtual (neste artigo usei o chatgpt, e penso usar outros no futuro para comparar). Fiz alterações no texto, mas acho que se nota bem as secções que são 100% artificiais porque parecem anúncios e o português é um pouco “abrasileirado”.
Há alguns anos publiquei um artigo sobre a conversão de um modelo digital do terreno global para o sistema de coordenadas português e também cortado aos limites de Portugal Continental (https://blog.viasig.com/2010/03/mdt-30m-para-portugal/). Depois coloquei-o numa partilha online. Até hoje continua a ser procurado, embora tenha já feito várias referências para novos dados – melhores e mais atuais.
Este mdt tem 25m de resolução, com um erro médio quadrático de +-7m!! O que me parece excelente.
Nota técnica – na realidade estes dados não são um mdt, mas sim um mds – modelo digital da superfície, ou seja, não representam a cota do terreno e sim o topo dos objetos na superfície, como árvores e edifícios e outras estruturas. Mas mesmo isto não é bem correto no caso do eu-dem… Aparentemente, estes dados podem representar o topo de objetos, como árvores e estruturas, mas, por outro lado, como sinais radar (usados na missão original) podem penetrar a canópia das árvores, também não há certeza que os dados representem a cota do topo das árvores.
Este artigo é muito simples – pretende disponibilizar uma versão pronta a usar para Portugal. Nada de especial – vamos apenas derivar uma versão que estará projetada para o nosso sistema de coordenadas, e cortada à extensão do nosso país (continente), usando apenas o QGIS. No fim do artigo há um link para descarregar os dados finais preparados para Portugal.
TLDR: Neste post discutimos formas de acelerar o processo de criação de overviews, e no fim usamos um script que reduz o tempo de processamento em 20%-50%. O script é apresentado abaixo e está no github.
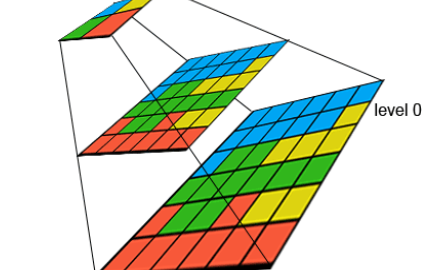
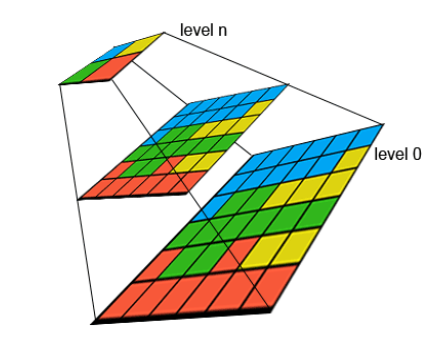
Na visualização de rasters é obrigatório construir as overviews ou pirâmides, para conseguirmos uma visualização rápida.
As overviews são uma série de cópias do nosso raster com resoluções cada vez menores (pixeis maiores), e geralmente cada nível aplica uma redução de 50% na resolução. Por exemplo, numa resolução original de 0,30m/pixel, as overviews são imagens com resoluções de 0,60 – 1,20 – 2,40m/pixel e assim sucessivamente até que não faz sentido reduzir mais a imagem.
Overviews ou pirâmides permitem uma visualização rápida de rasters, através de imagens de resolução reduzida. (Obitdo em: https://eurogeographics.org/wp-content/uploads/2018/04/WCS-NLSS.pdf.)
Em geral, a construção destas pirâmides é feito com o comando gdaladdo, e é o processo mais moroso quando processamos grandes áreas. Nem a conversão com compressão, nem a união de muitos rasters leva tanto tempo.
Actualmente, com discos SSD rapidíssimos e memória super-abundante, e processadores multi-core, o comando gdaladdo que constrói overviews continua a usar apenas 1 core… por outro lado, é mais lento que outros comandos, como o gdal_translate.
Recentemente processei novos mosaicos para o Alentejo, desta vez com ortofotomapas com 0,30m de resolução, rgb+nir. E, claro, construir overviews foi uma tortura… mais de 8h para cada metade (dividi a área em 2 blocos este/oeste). O processador nunca passou dos 17% (i7 de 4 cores/8threads), e o disco SSD nunca passou de uns miseráveis 5MB/s (quando o disco é capaz de 1000MB/s). Muito frustrante…
O processo que uso consiste sempre em manter os ficheiros independentes, e criar um mosaico .vrt. Por hábito não crio mosaicos tif enormes. Este processo é descrito em artigos anteriores.
Depois de pesquisar online, vi 3 sugestões para melhorar o tempo de criar overviews:
Criar imagens de resolução reduzida, usando o gdal_translate, e renomear estas imagens com extensão .ovr repetida, ou seja, mosaico.vrt.ovr, depois mosaico.vrt.ovr.ovr, e sucessivamente. Embora com ficheiros a mais, pareceu-me muito rápido.
Isto ensinou-me uma série de coisas novas:
Os ficheiros .ovr são na verdade ficheiros TIFF multi-página (herança do tempo dos faxes!), onde um tiff é “colado” a outro dentro do mesmo ficheiro. Eu não sabia isto sobre os .ovr. Ou seja, cada resolução é um tiff, dentro do ovr, que é também um tiff (matrioska?).
É possível juntar vários tiff num só tiff multi-página usando o comando “tiffcp tiff1 tiff2 tiffunido”.
O OSGEO4W inclui uma versão “geo-activada” dos comandos tiff, mantendo as características SIG dos ficheiros.
Podemos ter overviews de overviews, juntando a extensão .ovr ao ficheiro .ovr anterior, numa sucessão que funciona em gdal, qgis, e arcgis. Deve funcionar nos restantes programas, como geoserver, mapserver, etc.
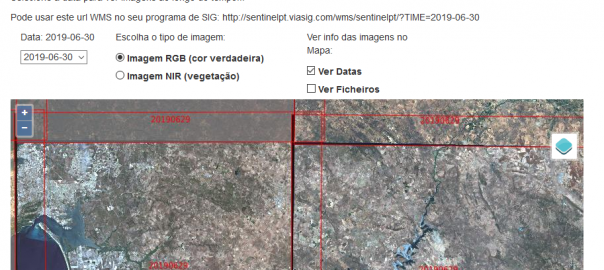
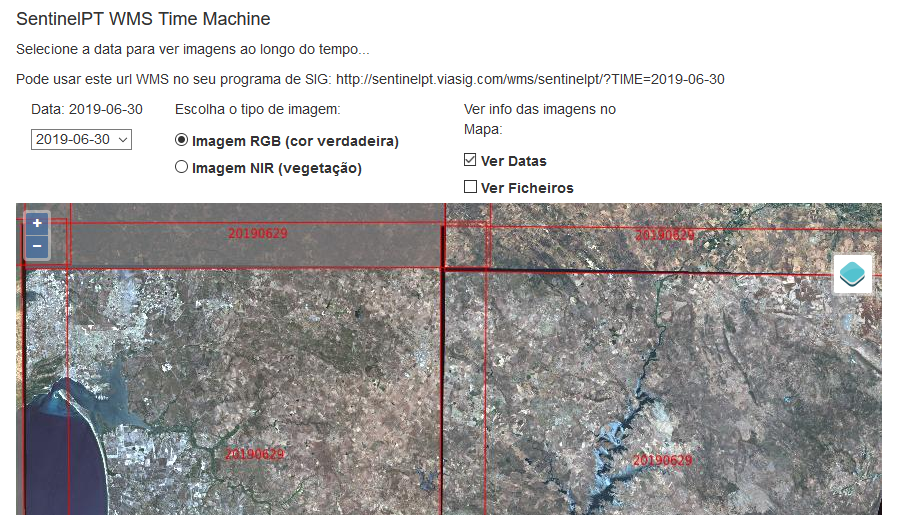
Podem aceder aqui a um motor de mosaicos de imagens Sentinel-2 RGB e IRG para Portugal, com serviço WMS, com suporte temporal… O serviço WMS está funcional, mas para usar em QGIS é preciso algumas definições (ler abaixo, muuuito abaixo).
Alguns avisos: isto é um projecto pessoal, de carolice, tem muitos defeitos, eu sei, que podem ou não vir a ser resolvidos… Estou muito interessado em ouvir sugestões, e para isso nada melhor que o twitter ou os comentários aqui no blog.
Se a carga for demasiada no servidor, os pedidos são “desacelerados”, por forma a manter o servidor equilibrado. Por favor, não usem scripts de download… Pretendo incluir a função de download em breve. Entretanto, se precisarem de alguma imagem é só dizer, eu farei os possíveis para responder atempadamente.
E pronto, agora quem tem curiosidade e paciência pode continuar a ler…
Este post resulta de eu ter cometido este erro há muito tempo atrás (v8.4) e só agora estar a pagar por ele…
Como funcionam os tablespaces no postgres?
Tablespaces em pgsql são pastas onde são colocados os ficheiros de dados, e a teoria é que permitem espalhar os dados em diferentes discos para equilibrar os acessos e o desempenho. Também dão flexibilidade para gerir falta de espaço em disco, p.e. colocando um tablespace noutro disco que tem espaço, e que receberá determinados dados (todos os novos dados, só algumas tabelas, etc.). Esta divisão também pode ser feita quando temos só um disco, ficando a bd preparada para um cenário futuro com mais discos.
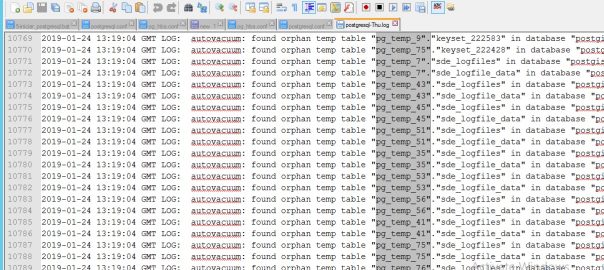
Quando o postgresql termina abruptamente de forma anormal, geralmente recupera sem problemas. Mas recentemente sucedeu-me que no log apareciam milhares de mensagens deste tipo:
2019-01-24 13:31:39 GMT LOG: autovacuum: found orphan temp table "pg_temp_56"."sde_logfile_data" in database "postgis"
Aparentemente estas mensagens são escritas pelo menos todos os segundos, o que degrada o desempenho e aumenta o tamanho dos logs.
Para resolver, basta apagar os schemas tablespaces problemáticos:
DROP SCHEMA pg_temp_56;
Estes schemas tablespaces “especiais” podem ser listados assim:
select relname,nspname from pg_class join pg_namespace on (relnamespace= pg_namespace.oid) where pg_is_other_temp_schema(relnamespace);
E confirmando com as mensagens de log, podemos apagar apenas aqueles de que o autovacuum se queixa.
Ao procurar na web, esta queixa não é muito frequente, mas acontece [1]. E nas listas de mail do postgresql [2], vemos até um debate acesso entre os programadores do postgres sobre se continuam a debitar este n.º exagerado de mensagens ou se devem limitar ou eliminar mesmo as mensagens. A opção actual é jogar pelo seguro – manter, para que os responsáveis pela base de dados notem que algo se passa e se preocupem o suficiente para corrigir a situação.
Comigo funcionou…
Evitar conexões…
É conveniente apagar estes schemas tablespaces tendo a certeza de que não há conexões à bd… Para isso, basta editar o ficheiro pg_hba.conf de forma a permitir apenas conexões do localhost.
Devemos comentar as linhas que dão acesso à bd de outros endereços, e deixar ou incluir apenas as linhas que dão acesso ao localhost. Um exemplo seria:
#IPv4 local connections: host all all 127.0.0.1/32 md5 #IPv6 local connections: host all all ::1/128 md5 #INTRANET - comentado temporariamente #host all all 192.168.0.0/16 md5 #host all all 10.10.0.0/16 md5
Reiniciamos o serviço do postgresql o que provocará o fecho de todas as conexões, e o assumir da nova configuração, impedindo conexões indesejadas. No meu caso, antes disto, parei o servidor web e o servidor de mapas. Só para ser simpático e não deixar aplicações em estados de erro…
Depois de apagar os schemas tablespaces, devemos reiniciar o serviço postgresql, e verificar se no log aparecem mais avisos deste tipo, porque o autovacuum é também iniciado. Se sim, apagamos os schemas tablespaces em erro.
Quando tudo estiver ok, revertemos o pg_hba.conf para permitir novamente conexões, e reiniciamos o serviço postgresql. Testamos uma aplicação qualquer para vermos se tudo está bem. Vamos para casa ter com a família…
Tempo de leitura: 5minEste artigo é o 2º da série sobre virtualização com LXD. O 1º artigo fez uma introdução rápida ao lxd.
Já tenho todas as minhas aplicações web instaladas em containers LXD separados, numa vps de 3gb ram e 4 vcores, baseada em kvm. Comprei na última black friday e custa-me 5€/mês. Quem estiver à procura de vps baratas recomendo verem aqui: https://lowendbox.com/.
A máquina “dncplex” é o meu servidor de música, com plex server e o fantástico MyMedia for Alexa! que permite aceder à minha biblioteca de música no meu Echo!
A “planetasig” é obviamente o PlanetaSIG, e a “viasigwp” é este mesmo blog.
Como tive sempre receio de upgrades de versões major no wordpress fui adiando o upgrade da v3 para a v4. E esta já vai na v4.9.5. Está mesmo na altura de fazer o upgrade à prova de falha.
Uma vez que uso o lxd, o plano é copiar o container para um novo, e fazer aí o upgrade. Se correr bem, paro o container antigo v3, e fico com o novo já com o wordpress v4. Se correr mal, apago e recomeço, ou desisto e fico na mesma… risco 0… Continuar a lerLXD – upgrades sem riscos→
Tempo de leitura: 8minEste post é sobre o LXD, uma forma de criar “máquinas virtuais” que residem em directorias na nossa máquina, sem mais intermediários (hypervisors). Para quem usa docker podem ver mais info sobre o projecto e como se comparam os 2: https://www.ubuntu.com/containers/lxd.
Fica já a nota que o docker e o lxd são concorrentes, mas talvez sejam mais complementares. O docker isola componentes, o lxd isola sistemas operativos. Terão por isso vantagens e desvantagens muitas vezes simétricas. E ambos são similares na tecnologia de base que usam (lxc e chroot + cgroups). Basicamente, usam capacidades do kernel linux para isolar componentes (é por isso que só podemos “virtualizar” componentes linux e não windows ou mac). Na verdade, e para ser tecnicamente menos incorrecto, não se criam máquinas virtuais, mas sim containers. Mas para simplicidade, no resto do texto quando falo de containers ou VM’s é tudo o mesmo… containers.
Aquilo que me entusiasma no LXD é a simplicidade de uso, com muito poucos comandos, e a facilidade de gerir sistemas que integram vários componentes, como geralmente acontece numa plataforma SIG (qgis, postgresql, geoserver, etc.). Como o LXD virtualiza um SO inteiro, é natural e fácil usá-lo para conter sistemas aplicacionais inteiros.
As máquinas LXD podem ser criadas em directorias no nosso servidor Ubuntu, e podem conter diversos sistemas operativos. E é muito fácil clonar, fazer snapshots, parar e iniciar estes contentores de SO. Já cópias de segurança obrigam a alguma ginástica, mas estão a trabalhar num método simplificado.
Também é fácil limitar os recursos usados por cada VM, quer na memória máxima, quer no processador (cores, % de tempo, etc.), e vários outros recursos. Podem ver info completa aqui: https://stgraber.org/2016/03/26/lxd-2-0-resource-control-412/.
A existência do LXD vem baixar a complexidade da virtualização baseada em containers, deixando de usar hypervisors como o KVM, OpenVZ, VMWare, VirtualBox, e HyperV.
Podemos instalar o Ubuntu directamente na máquina física, e criar VM’s usando comandos LXD. Os seus defensores indicam ganhos de desempenho, ou mais correctamente menos perda de desempenho, e por isso potencial maior densidade de VM’s. Não posso confirmar nem desmentir porque não testei nada disto. Mas parece-me algo lógico.
Só mais um detalhe – o LXD suporta nested virtualization, ou seja, dentro de uma VM Ubuntu podemos usá-lo para criar VM’s, que estão dentro da nossa VM inicial… confuso? Cuidado, que o OpenVZ não suporta lxd… portanto ao comprarem uma VPS assegurem-se que é baseada em KVM.
Tempo de leitura: 6minUma das formas de medir o desempenho do PostgreSQL no nosso servidor, é usar o pgbench, a ferramenta padrão incluída com a instalação do pgsql. Há tempos fiz uns testes de comparação de 2 servidores que publiquei aqui: https://blog.viasig.com/2014/08/medir-o-desempenho-do-postgresql/.
Ora, esses testes usam dados alfanuméricos e queries “normais”, de escrita e leitura, usando tabelas relacionadas. Ou seja, o pgbench tenta simular uma utilização usual do pgsql.
No nosso caso, SIGianos, a utilização usual não tem nada a haver – usamos dados espaciais e queries muito próprias. Este artigo mostra uma forma de medirmos o desempenho do PostGIS, usando também a ferramenta pgbench.
Uso “normal” de SIG
Quando um programa “normal”, não geográfico, consulta uma base de dados, em geral, obtém alguns registos, e pode até cruzá-los, para dar um resultado final. Provavelmente, apresenta uma tabela de resultados, paginados, com algumas colunas (menos de 10?). Um bom exemplo, é um programa de facturação ou de gestão de stocks. É este tipo de programas que o pgbench tenta simular.
Há uma enorme diferença para o uso que um programa de SIG faz de uma base de dados. O uso normal SIG é visualizar um mapa. E isso faz toda a diferença.
Este simples mapa de enquadramento usa 7 tabelas. A área visível usa um total de 618 registos (1+261+177+1+3+29+146). Se visualizarmos o país inteiro, a conta passa para 5841 registos. É muita informação para uma das operações mais básicas – pan e zoom.
Do ponto de vista da base de dados, o uso SIG é diferente:
Um mapa é, tipicamente, composto por diversos temas (facilmente mais de 10);
Cada tema é uma tabela espacial diferente na base de dados, logo em cada visualização vamos ler uma série de tabelas;
Cada tema/tabela pode ser lido na totalidade (não paginado) se visualizarmos toda a área do tema;
Cada tema/tabela pode ter aplicada uma selecção (filtro) logo de início com base nos atributos (e.g. para vermos apenas uma categoria de rios ou estradas);
Cada tema/tabela pode ainda ter aplicado um filtro espacial se estivermos a visualizar apenas uma área específica (ou seja, são apenas pedidos os dados relativos ao rectângulo visível no mapa);
Mas, principalmente, os dados geográficos são muitos mais “pesados” ou “gordos”: têm uma coluna que contém todos os vértices da geometria! (Cada vértice tem 2 números do tipo double, o que equivale a 2 colunas em dados alfanuméricos.)
Para agravar a coisa, os utilizadores nunca escolhem os campos que precisam para trabalhar, e assim quando abrem a tabela de atributos todos os campos são lidos.
Usar o pgbench para simular utilizadores SIG
Uma das capacidades do pgbench é que permite testar queries à base de dados feitas por nós, em vez de usar as pré-definidas. Basta criar um ficheiro sql que contém as nossas queries e passá-lo ao pgbench com o parâmetro –f. Continuar a lerMedir o desempenho do PostGIS→
Tempo de leitura: 4minO MapServer é geralmente instalado com Apache, mesmo em Windows. Para este caso, basta um dos vários instaladores existentes, por exemplo, o OSGeo4W.
Mas, no meu caso e imagino muitos outros, como uso mais servidores Windows, precisei de instalar o MapServer de forma a que funcione com IIS. Para além disto, preciso também que o endereço web dos meus mapas não mostre sempre o ficheiro de configuração usado. É feio, e é um risco de segurança. Ninguém devia saber a estrutura das directorias no disco rígido do servidor.
MapServer como aplicação FastCGI – As melhores instruções
A parte inicial de configurar o IIS de forma a executar o MapServer é mais ou menos fácil de encontrar na net. Esta parte consiste em configurar o IIS de forma a considerar o executável mapserv.exe como sendo uma aplicação FastCGI. Isto é mais ou menos padrão nos IIS >7.0 (win7/win8/win2008/win2012). Este link explica bem como fazer isto, usando os ficheiros do MS4W:
Eu preferi fazer uma instalação manual, usando ficheiro zip do Tamas Szekeres contendo todo o software, em vez do .msi. Isto dá-me mais flexibilidade para encontrar a configuração que mais se ajusta às minhas necessidades.