Tempo de leitura: 8 minNeste artigo a expressão “Servidores SIG” refere-se a servidores de mapas online (ou webgis). A questão que se coloca é: medir a performance do nosso servidor ArcIMS, MapServer, ArcGIS Server, GeoServer, etc.
Em geral podemos considerar que temos um bom servidor se for capaz de produzir 2 mapas por segundo. As aplicações webgis são muito interactivas, e um utilizador quando faz zoom não quer ficar à espera muito tempo até que o mapa volte a ser redesenhado.
Claro que desde 2005, com o aparecimento das aplicações baseadas em pequenas quadrículas (tiles) já pré-processadas e prontas no disco rígido do servidor para serem mostradas ao utilizador, a exigência sobre o dinamismo das aplicações tradicionais (sem tiles) subiu em flecha. Mas não é uma exigência justa… (Pelo menos do ponto de vista técnico – do ponto de vista do utilizador “isso não interessa nada”.)
Um mapa que é gerado dinamicamente necessita sempre de mais tempo para ser processado. Basta pensar em todas as tarefas que têm de ser executadas até chegar à imagem final: ler a configuração do mapa, obter os dados para a zona visível, desenhar os dados, e gravar a imagem. Isto comparando com a abordagem com tiles: 1) qual é a imagem que é preciso mostrar? 2) Ahh, é esta. Portanto, um servidor que consegue debitar 2 mapas dinâmicos por segundo é muitíssimo bom, e se o seu servidor não conseguir tanta velocidade não lhe leve a mal.
Recentemente, tive a boa sorte de poder contar com um novo servidor para suportar todas as aplicações webgis de um SIG empresarial, e tenho andado no processo de instalação do software e de migração das aplicações que estão no servidor “velho”. Embora a nova configuração seja muito mais moderna, afinal passaram 5 anos, o novo processador tem menos 1,2GHz de velocidade de relógio e isso, confesso, deixou-me apreensivo. Decidi que haveria que medir o desempenho dos 2 servidores. Quem não tiver interesse em ler todo o artigo pode sempre saltar para as conclusões.
Configurações dos servidores em comparação
O servidor “velho” tem um processador Xeon a 3,2 GHz baseado no Pentium 4, Windows Server 2003, com 2GB de memória.
O novo servidor tem um Xeon moderno a 2,0 GHz baseado no Core 2, Windows Server 2003 64 bit, e com 8 GB de memória.
Os discos que equipam ambos os servidores não serão muito influentes no teste uma vez que todos os dados usados residem numa base de dados Oracle/ArcSDE numa máquina separada, à qual ambos os servidores se ligam por rede a 1 Gbps. Em relação à memória, vamos desprezar o efeito que poderá ter, uma vez que a máquina mais antiga teve sempre memória de sobra mesmo só com 2 GB.
O software usado como servidor SIG é o ArcIMS da ESRI. No servidor “velho” está instalado a versão 9.2, e no novo a versão 9.3. Ambos os servidores usam o IIS e o Tomcat.
O serviço de mapas usado para o teste contém uma mistura de dados vectoriais de de imagem (ortofotomapas com 0,4m de resolução), e usa simbologia bastante complexa, com labels, e anti-aliasing. É portanto um serviço que se pode considerar bastante exigente ao nível de processamento.
Software de Testes – JMeter
Já há algum tempo que procurava uma aplicação que me permitisse efectuar testes de desempenho em ambiente web, mas que fosse fácil e prático, sem grandes manuais e configurações… o JMeter encaixa perfeitamente nestes requisitos. É uma aplicação Java desenvolvida pelo grupo Apache, é Open Source, logo gratuito. Tem uma boa documentação, e encontram-se vários exemplos de iniciação na Internet.
A forma de funcionar é muito simples. Um teste é composto por painéis que vamos adicionando. Cada painel é de um determinado tipo e serve uma função: definir parâmetros default, executar um pedido via HTTP, agregar resultados num relatório, e até efectuar operações mais complexas como definir variáveis, ciclos, estruturas de decisão if-then, usar ficheiros csv com parâmetros, etc. É uma ferramenta que pode ser usada tanto de forma muito simples (o meu caso) como de forma muito complexa.
Mas a cereja no topo do bolo é a capacidade do JMeter gravar o que fizermos no browser, e depois usar essa gravação para bombardear o servidor, repetindo a mesma sessão mas multiplicando-a como se existissem vários utilizadores simultâneos.
Gravando um teste
Para gravar uma sessão de utilização do browser, basta iniciar o JMeter e adicionar ao nosso “Workbench”, um painel “HTTP Proxy Server”. Com este painel, o JMeter vai capturar tudo o que fizermos no Internet Explorer, construindo assim o nosso teste. Depois basta retirar o que não é essencial, como imagens jpeg ou gif, ficheiros html, js, e restante conteúdo estático, que é processado pelo servidor web (IIS, Apache) e não pelo nosso servidor SIG. Em seguida, na entrada “Test Plan” acrescenta-se um “Thread Group”. Este item é o contentor de todos os passos do nosso teste. O Thread Group define o n.º de utilizadores simulados e o n.º de repetições que cada utilizador fará (Loop Count).
Com estas definições, usamos a opção Run/Start, e de seguida iniciamos o IE e abrimos uma aplicação de mapas que esteja no nosso servidor. No meu caso, usei o visualizador “HTML Viewer” que é instalado com o ArcIMS. Fiz alguns zooms e pans, e para terminar um Identify. De seguida bastou parar o JMeter com a opção Run/Stop. O teste ficou com o seguinte aspecto (já com todos os nossos passos gravados):
Alterar o teste de desempenho
Em seguida, apagam-se todos os passos que não sejam pedidos directos ao ArcIMS. Os pedidos ao ArcIMS têm endereços que apontam para algo como “/servlet/Esrimap”… o objectivo é testar apenas os conteúdos que são direccionados ao servidor de mapas e não ao servidor web.
No final, acrescenta-se um painel “Aggregate Report”, que vai recolher automaticamente os resultados dos vários passos do teste. No final, ficaremos a saber o n.º de pedidos efectuados, a média de tempo de processamento, tempos mínimo e máximo, KB/s transmitidos e n.º de pedidos processados por segundo. Mais à frente veremos os resultados e a interpretação que se pode fazer para se chegar ao n.º de mapas/s.
O teste resultante ficou com o seguinte aspecto:
É claro que também teremos de apagar o HTTP Proxy Server…
Resta-nos correr o teste. Gravam-se as estatísticas do relatório usando o botão “Save Table Data”, e alteram-se os endereços para apontarmos para o novo servidor. Repete-se o teste, e gravam-se as novas estatísticas para outro ficheiro.
Testando
No meu caso particular, executei 2 testes em cada servidor – um em que se simulou só um utilizador, e outro em que se simularam 10 utilizadores simultâneos. Os zooms foram feitos sempre aos mesmos locais, com exactamente as mesmas coordenadas. Geralmente, isto não é desejável, principalmente quando se quer testar a performance de uma aplicação ou medir o impacto das melhorias espectaculares que fizemos ao nosso serviço de mapas. Mas no caso em mãos, o objectivo é comparar 2 servidores, e o facto de se pedir sempre mapas das mesmas áreas faz com que os dados usados sejam sempre os mesmos, eliminando-se variações de desempenho no seu acesso. Acresce que ao usarmos uma base de dados, os mecanismos de cache da mesma irão entrar em pleno funcionamento, atenuando ainda mais qualquer flutuação na velocidade de acesso à informação.
Resultados e análise com 1 utilizador
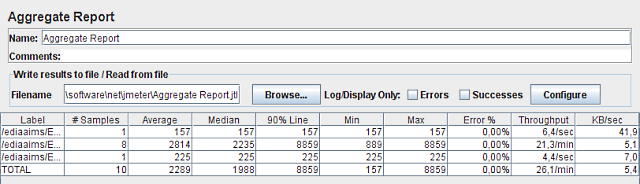
Para o teste de 1 conexão obtivemos os seguintes resultados para a máquina antiga:
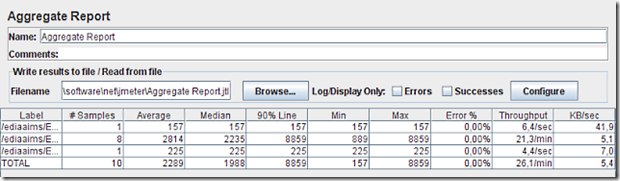
A 1ª linha é o pedido inicial feito ao ArcIMS para obtermos a lista de layers no mapa, extensão geográfica inicial, e outros dados genéricos. É um pedido que foi processado muito rapidamente, demorando 157 ms.
A 3ª linha é o pedido final de Identify. É também muito rápido, tendo o servidor demorado 225 ms a devolver os atributos do vector que se encontrava sob o ponto clicado.
A 2ª linha é a mais interessante: aglomera os 8 pedidos de mapa, em 8 locais diferentes e a escalas diferentes. Aqui o servidor teve de trabalhar mais: demorou um mínimo de 889 ms, e um máximo de 8859 ms, ou seja 8,9 s! Quando esta imagem chegou já o utilizador tinha ido tomar café!! Se virmos o final desta linha temos o valor de 21,3/min que significa que com base nestes 8 resultados estima-se que o servidor conseguirá processar 21,3 mapas por minuto. Ou seja, 1 mapa demora em média 2,8 segundos a ser processado.
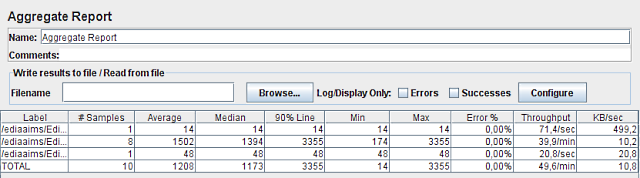
E para a nova máquina, obtivemos os seguintes resultados:
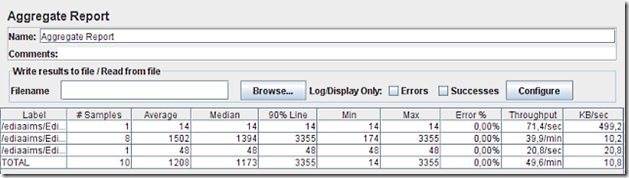
Ignorando os valores das 1ª e 3ª linhas, vamos directos ao que interessa – a 2ª linha.
Este servidor demorou um mínimo de 174 ms e um máximo de 3355 ms para gerar cada uma das imagens pedidas. E a sua capacidade estimada a partir destes resultados é de 39,9 mapas por minuto. Ou seja, 1 mapa demorou em média 1,5 segundos a ser processado.
É preciso aqui introduzir 2 notas: i) o mapa que demora tanto tempo a produzir é o mapa inicial, que mostra uma panorâmica regional, tem de desenhar muitos dados, e deveria por isso ser optimizado. ii) apenas se considerou 1 utilizador, e portanto nenhum dos servidores terá sido usado na sua capacidade máxima.
Resultados e análise com 10 utilizadores
Repetiram-se os testes agora indicando ao JMeter que seriam simulados 10 utilizadores, e cada um faria 5 repetições, totalizando assim 500 pedidos a cada servidor.
Para a máquina “velha” obtiveram-se estes resultados:
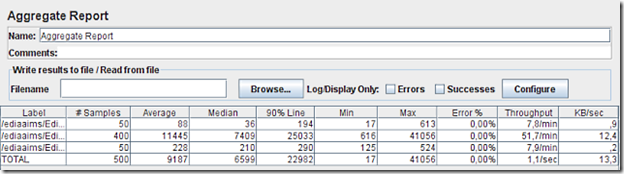
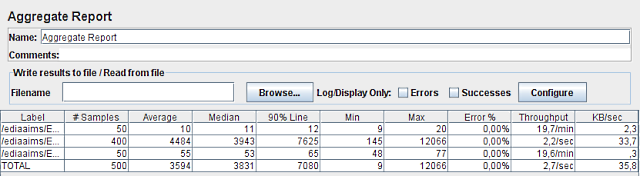
Com 10 utilizadores simulados já começam a aparecer números mais interessantes (2ª linha): mínimo de 616 ms, máximo de 41056 ms! O tempo de espera médio por cada mapa subiu para 11,4 segundos! Mas processaram-se mais mapas por minuto subindo para 51,7 mapas/min. O problema é que com este número de pedidos simultâneos o servidor está claramente a funcionar acima da sua capacidade de processamento, e demora demasiado tempo a processar cada um.
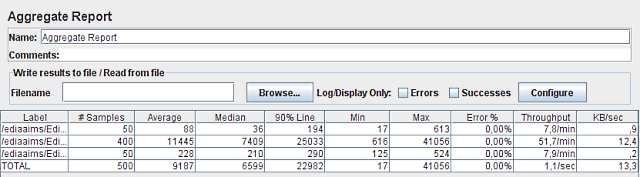
Para a nova máquina obtiveram-se os seguintes números:
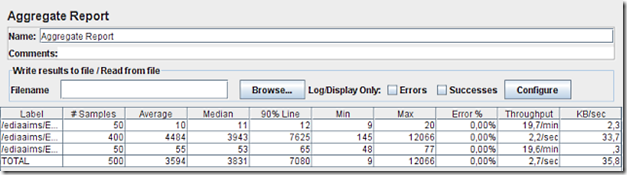
Com 10 utilizadores, o novo servidor obteve um mínimo de 145 ms e um máximo de 12066 ms. O tempo mínimo desceu, o que indicaria que o servidor teve capacidade de processamento suficiente para tantos pedidos, mas o tempo máximo quadruplicou, o que indicaria o oposto… E o tempo médio também triplicou chegando a 3,9 segundos por cada mapa gerado, o que também indica alguma sobrecarga. No entanto, foram processados 2,2 mapas por segundo!! O que é bastante impressionante – chegamos assim à marca mágica de 1 mapa em ½ segundo!
O novo servidor baseado num Xeon Core 2 com 4 cores e a 2,0GHz é muito mais rápido com o ArcIMS do que o antigo servidor baseado num Xeon Pentium 4 a 3,2GHz. Vejamos o resumo dos resultados dos testes de 1 utilizador e de 10 utilizadores:
| |
Mapas/min
|
KB/s
|
Mapas/min
|
KB/s
|
|
Xeon P4 3,2GHz
|
21,3
|
5,1
|
51,7
|
12,4
|
|
Xeon Quad 2GHz
|
39,9
|
10,2
|
132
|
33,7
|
|
melhoria %
|
87%
|
100%
|
155%
|
172%
|
| |
1 utilizador
|
10 utilizadores
|
Ou seja, com 1 único utilizador ligado, o novo Xeon Quad 2GHz foi capaz de processar mais 87% de mapas por minuto que o Xeon P4 3,2GHz. E com 10 clientes simultâneos o novo Xeon Quad foi capaz de processar mais 155% mapas por minuto!!
Além disso, enquanto que o Xeon P4 manteve a ocupação do cpu entre 76% e 94% (mais à volta dos 90%), o novo Xeon Quad manteve-se entre 30% e 58% (mais à volta dos 50%), distribuindo a carga pelos 4 cores, e nunca chegando aos 60% da capacidade de processamento. Haveria a possibilidade de afinar a configuração do ArcIMS para que use melhor todos os 4 cores, mas não era esse o objectivo, pelo contrário – pretendeu-se limitar o ArcIMS a 1 core no novo Xeon Quad para melhor comparar os 2 processadores. Claramente este objectivo não foi totalmente conseguido e a carga de processamento foi dividida pelos vários cores, sendo por isso uma comparação injusta com o Xeon P4 de 1 core apenas. No entanto, os números obtidos no teste de 1 utilizador simulado permitem uma comparação mais justa, e aqui é inegável a superioridade do novo processador, mesmo com uma velocidade de relógio 30% inferior.
Concluindo, mesmo funcionando com menos 1,2GHz o Xeon Quad Core é muito superior, obtendo um resultado 87% superior no teste mais “suave”. Impressionante…