Há alguns anos publiquei um artigo sobre a conversão de um modelo digital do terreno global para o sistema de coordenadas português e também cortado aos limites de Portugal Continental (https://blog.viasig.com/2010/03/mdt-30m-para-portugal/). Depois coloquei-o numa partilha online. Até hoje continua a ser procurado, embora tenha já feito várias referências para novos dados – melhores e mais atuais.
Este mdt tem 25m de resolução, com um erro médio quadrático de +-7m!! O que me parece excelente.
Nota técnica – na realidade estes dados não são um mdt, mas sim um mds – modelo digital da superfície, ou seja, não representam a cota do terreno e sim o topo dos objetos na superfície, como árvores e edifícios e outras estruturas. Mas mesmo isto não é bem correto no caso do eu-dem… Aparentemente, estes dados podem representar o topo de objetos, como árvores e estruturas, mas, por outro lado, como sinais radar (usados na missão original) podem penetrar a canópia das árvores, também não há certeza que os dados representem a cota do topo das árvores.
Este artigo é muito simples – pretende disponibilizar uma versão pronta a usar para Portugal. Nada de especial – vamos apenas derivar uma versão que estará projetada para o nosso sistema de coordenadas, e cortada à extensão do nosso país (continente), usando apenas o QGIS. No fim do artigo há um link para descarregar os dados finais preparados para Portugal.
Tempo de leitura: 6minUma das formas de medir o desempenho do PostgreSQL no nosso servidor, é usar o pgbench, a ferramenta padrão incluída com a instalação do pgsql. Há tempos fiz uns testes de comparação de 2 servidores que publiquei aqui: https://blog.viasig.com/2014/08/medir-o-desempenho-do-postgresql/.
Ora, esses testes usam dados alfanuméricos e queries “normais”, de escrita e leitura, usando tabelas relacionadas. Ou seja, o pgbench tenta simular uma utilização usual do pgsql.
No nosso caso, SIGianos, a utilização usual não tem nada a haver – usamos dados espaciais e queries muito próprias. Este artigo mostra uma forma de medirmos o desempenho do PostGIS, usando também a ferramenta pgbench.
Uso “normal” de SIG
Quando um programa “normal”, não geográfico, consulta uma base de dados, em geral, obtém alguns registos, e pode até cruzá-los, para dar um resultado final. Provavelmente, apresenta uma tabela de resultados, paginados, com algumas colunas (menos de 10?). Um bom exemplo, é um programa de facturação ou de gestão de stocks. É este tipo de programas que o pgbench tenta simular.
Há uma enorme diferença para o uso que um programa de SIG faz de uma base de dados. O uso normal SIG é visualizar um mapa. E isso faz toda a diferença.
Este simples mapa de enquadramento usa 7 tabelas. A área visível usa um total de 618 registos (1+261+177+1+3+29+146). Se visualizarmos o país inteiro, a conta passa para 5841 registos. É muita informação para uma das operações mais básicas – pan e zoom.
Do ponto de vista da base de dados, o uso SIG é diferente:
Um mapa é, tipicamente, composto por diversos temas (facilmente mais de 10);
Cada tema é uma tabela espacial diferente na base de dados, logo em cada visualização vamos ler uma série de tabelas;
Cada tema/tabela pode ser lido na totalidade (não paginado) se visualizarmos toda a área do tema;
Cada tema/tabela pode ter aplicada uma selecção (filtro) logo de início com base nos atributos (e.g. para vermos apenas uma categoria de rios ou estradas);
Cada tema/tabela pode ainda ter aplicado um filtro espacial se estivermos a visualizar apenas uma área específica (ou seja, são apenas pedidos os dados relativos ao rectângulo visível no mapa);
Mas, principalmente, os dados geográficos são muitos mais “pesados” ou “gordos”: têm uma coluna que contém todos os vértices da geometria! (Cada vértice tem 2 números do tipo double, o que equivale a 2 colunas em dados alfanuméricos.)
Para agravar a coisa, os utilizadores nunca escolhem os campos que precisam para trabalhar, e assim quando abrem a tabela de atributos todos os campos são lidos.
Usar o pgbench para simular utilizadores SIG
Uma das capacidades do pgbench é que permite testar queries à base de dados feitas por nós, em vez de usar as pré-definidas. Basta criar um ficheiro sql que contém as nossas queries e passá-lo ao pgbench com o parâmetro –f. Continuar a lerMedir o desempenho do PostGIS→
Tempo de leitura: 4minO MapServer é geralmente instalado com Apache, mesmo em Windows. Para este caso, basta um dos vários instaladores existentes, por exemplo, o OSGeo4W.
Mas, no meu caso e imagino muitos outros, como uso mais servidores Windows, precisei de instalar o MapServer de forma a que funcione com IIS. Para além disto, preciso também que o endereço web dos meus mapas não mostre sempre o ficheiro de configuração usado. É feio, e é um risco de segurança. Ninguém devia saber a estrutura das directorias no disco rígido do servidor.
MapServer como aplicação FastCGI – As melhores instruções
A parte inicial de configurar o IIS de forma a executar o MapServer é mais ou menos fácil de encontrar na net. Esta parte consiste em configurar o IIS de forma a considerar o executável mapserv.exe como sendo uma aplicação FastCGI. Isto é mais ou menos padrão nos IIS >7.0 (win7/win8/win2008/win2012). Este link explica bem como fazer isto, usando os ficheiros do MS4W:
Eu preferi fazer uma instalação manual, usando ficheiro zip do Tamas Szekeres contendo todo o software, em vez do .msi. Isto dá-me mais flexibilidade para encontrar a configuração que mais se ajusta às minhas necessidades.
Tempo de leitura: 6minNão é todos os dias que temos a oportunidade de fazer um upgrade ao nosso velhinho servidor de PostGIS. Quando um servidor usado fica disponível ou, ainda melhor, quando recebemos uma máquina novinha em folha para instalar a nossa base de dados, queremos saber qual a melhoria de desempenho que vamos ter. Pelo menos eu quero
Por outro lado, se vamos comprar um novo servidor temos de definir as características dentro do preço que podemos pagar. E convém ter uma orientação que nos ajude a perceber que tipo de desempenho podemos obter dentro desse orçamento.
Outra utilidade para este tipo de medição é perceber quais os melhores parâmetros de configuração do PostgreSQL para a nossa nova máquina. Podemos alterar os parâmetros e testar, vendo rapidamente qual a combinação de parâmetros que melhor desempenho consegue.
Este artigo mostra como medir o desempenho do PostgreSQL usando o comando standard para isso – o pgbench. Para outro post fica a proposta de um teste standard para medir o desempenho da componente geográfica – PostGIS – usando o pgbench com dados geográficos disponíveis publicamente. Isto permite que todos os utilizadores de PostGIS possam usar um teste padrão, tal como já existe para dados não-espaciais, e comparar diferentes servidores.
O ideal seria ter uma tabela online onde se pudessem comparar vários servidores, editada pelos utilizadores… isso é que era!
Tempo de leitura: 3minEste artigo é um pouco periférico ao assunto central deste blog – a gestão de versões em projectos de programação.
O Problema Base
No mundo SIG há uma vertente de desenvolvimento de aplicações, das mais simples, como scripts que automatizam pequenos processos, até aplicações complexas web ou desktop.
Várias dificuldades mundanas se levantam ao longo de um projecto deste tipo, e talvez a mais importante seja: onde está a última versão?
Pessoalmente, uma questão com que me confronto frequentemente, quando preciso de voltar a trabalhar num programa/script/aplicação é bem simples: onde raio a tenho guardada, de entre os PCs e contas de utilizador que uso??? Raios! Ler artigo completo
Tempo de leitura: 9minOs ficheiros CAD são uma das principais fontes de dados para um SIG. Este artigo analisa as possibilidades actuais de lidar com CAD no Quantum GIS.
CAD e SIG
Existe uma rivalidade antiga entre quem trabalha com software CAD e quem trabalha com software SIG – é comum ouvirmos dizer coisas como “o CAD é menos avançado”, ou “os tipos do SIG têm a mania de complicar as coisas”, entre outros mimos. Na realidade CAD e SIG são ferramentas usadas para fazer coisas diferentes, com métodos de trabalho diferentes, e que (infelizmente) têm de conviver de forma muito próxima, sem se compreenderem muito bem… (Aviso: tentei ser isento, mas acho que desisti a meio do texto…)
Simbologia é informação
No CAD esta afirmação é verdadeira. No SIG não.
No CAD eu desenho os meus elementos gráficos com o objectivo principal de obter uma visualização – para ver no monitor ou para imprimir. Quanto mais produtivo for a criar a minha visualização melhor técnico CAD serei. Os elementos que crio no ficheiro CAD representam exactamente o que preciso de ver: uma árvore é constituída por uma copa, um poste de iluminação tem um pé e uma lâmpada, uma área ajardinada tem vários pequenos arbustos. Eu posso seleccionar cada um destes elementos e alterá-los para obter a visualização exacta que pretendo. Quando gravo um DWG ou um DGN gravo tudo isto – uma linha com dada cor, espessura, tipo de tracejado – gravo no ficheiro as geometrias que são também a simbologia em simultâneo. A estrutura do meu desenho é constituída pela forma como eu organizo os meus elementos por camadas (layers ou levels), e como crio os meus elementos (blocos ou elementos simples).
No SIG a situação é muito, muito semelhante. Mas 2 ligeiras diferenças são suficientes para tornar o diálogo entre as equipas CAD e SIG difícil e por vezes até antagónico.
1) No SIG eu desenho apenas geometrias. Recolho vértices XY. E recolho características das geometrias, que armazeno em atributos. Todas as geometrias que recolho num ficheiro têm sempre os mesmos atributos, e por isso descrevo-as de forma sistemática, formando uma tabela. Não há simbologia envolvida no processo. Ao gravar o trabalho num ficheiro de dados, guardo apenas vértices XY e atributos, sendo uma das razões por que grande parte do trabalho é focada em organizar informação, em decidir que atributos cada ficheiro terá. Mas esta obsessão organizativa vai mais longe! Cada ficheiro tem apenas um tipo de geometria – ponto, linha ou polígono – que nunca se misturam no mesmo ficheiro.
2) No SIG a simbologia é aplicada por regras a um ficheiro – não se define a simbologia de um só elemento. Usam-se os atributos para seleccionar um conjunto de geometrias a que depois aplicamos uma certa simbologia. Por exemplo, podemos representar especificamente as cidades com população maior que 1 milhão de habitantes como círculos pretos, as restantes cidades com um quadrado. Se todos os pontos que são as cidades tiverem um atributo com a sua população, o software SIG aplica esta simbologia facilmente. Uma consequência desta abordagem à simbologia é que passa a ser dinâmica. Se quisermos alterar a simbologia, não alteramos as geometrias – alteramos as regras da simbologia. Para guardar a simbologia usam-se ficheiros de projecto, que não têm dados, apenas regras e definições de como representar a informação e como a imprimir (formato da página, orientação, seta do norte, título, ou seja, o layout).
CAD
SIG
Exemplo de informação CAD original, e quando convertida para SIG.
Então qual é o problema?
Como dizem os políticos, ainda bem que fez essa pergunta…
Pois é, o problema é na conversão de CAD para SIG. Este é um assunto muito extenso e interessante, mas como é Verão apetece mais uma bejeca… 🙂 Mas ainda consigo lembrar-me de 3 grandes problemas nesta conversão:
1) Seleccionar num ficheiro CAD elementos que têm o mesmo significado é geralmente difícil. Se todos pontos que são as cidades estiverem num único layer, e nesse layer não existir outro tipo de pontos, então a sua selecção é facílima. Mas isso raramente acontece… geralmente elementos gráficos com diferentes significados coexistem no mesmo layer.
2) Determinar a posição correcta de um elemento é muitas vezes difícil – a cidade está no ponto de inserção do bloco, ou é o ponto central do bloco? O ponto cotado é o ponto de inserção, ou é a virgula decimal do texto da cota? E aqui junta-se a dificuldade de evitar as tramas ou “hatches”. (As tramas são linhas que representam simbologia mas não representam uma entidade no terreno. Geralmente aplicadas a polígonos, servem de arranjo gráfico, e não devem ser convertidas para SIG.) Outro exemplo são marcas quilométricas em eixos de infra-estruturas… no CAD são importantes, no SIG são considerados erros de conversão. Outro grupo de problemas pode ser aqui incluído – questões como converter linhas fechadas do CAD para polígonos no SIG, reconhecer vazios, e outras questões semelhantes…
3) E finalmente, recolher atributos juntamente com as geometrias é muitas vezes… … … difícil (novamente)! e para o SIG os atributos são fundamentais. Por exemplo, qual é a cota de cada ponto cotado ou curva de nível? Ou qual é o nome de cada eixo de rua? A verdade é que já foi feito o trabalho de recolha e digitalização desta informação pela equipa CAD, mas mesmo assim não é possível muitas vezes usá-la num SIG (ou noutro sistema qualquer). No CAD, o texto que mostra o nome de uma rua é uma entidade gráfica independente da linha, e por isso não existem métodos automáticos fiáveis para associar cada linha a cada texto. A não ser que se crie o ficheiro CAD já com a preocupação de permitir este tipo de interoperabilidade, e assim avançamos para tópicos de CAD avançados que (na minha experiência) escapam à maioria dos desenhadores.
Então e agora?
Pois é… agora estamos todos numa grande alhada. Ao fim de dias a tentar converter ficheiros CAD, o pessoal do SIG está pronto a abraçar uma vida de crime, começando por cometer uma série de homicídios lá para as bandas do CAD.
A única solução é conhecer bem o software que usamos. Com o tempo vamos aprendendo as técnicas que o software suporta para conseguir conversões cada vez mais automáticas. Mas tudo depende dos ficheiros originais CAD. E é muito importante poder contar com alguém no “lado” CAD que possa alterar os ficheiros CAD de forma a facilitar o processo de conversão.
Outra via de facilitar a vida a todos os técnicos envolvidos num processo que passe por CAD e SIG, é estabelecer regras para os ficheiros CAD que facilitem depois um processo menos manual de conversão. E isso novamente vai depender da informação em causa, e do tipo de AutoCAD em uso (“normal”, Map, Civil…). Por exemplo, no AutoCAD Map podemos criar Object Data, Object Class, ou até ligar os nossos elementos gráficos a tabelas de atributos externos, mas em AutoCAD “simples” isso já não é possível…
Portanto, não há regras infalíveis. Cada caso é um caso, como se diz. Mas há regras de bom senso que resultam sempre bem – agrupar elementos gráficos com o mesmo significado num só layer é uma dessas regras: só eixos de via num layer, e todos os eixos de via estão nesse layer (não há outros tantos eixos noutros tantos layers); cada layer tem um nome claro e intuitivo (nada de layers com nomes do tipo “ev_de” – que quereria dizer “eixos de via do distrito de évora”…); para layers de polígonos criar também o respectivo layer de anotação ou blocos de atributos (onde também marcamos os vazios), e outras regras deste género. Bom senso é muito subestimado hoje em dia…
QGIS
E finalmente chegamos à parte principal do artigo, que originou o seu nome…
O QGIS usa como leitor de dados as bibliotecas do GDAL (imagens) e OGR (vectores). Este facto não é muito visível para o utilizador, mas é importante para compreender as capacidades do QGIS. Estas bibliotecas têm drivers que são responsáveis por cada formato que o GDAL/OGR suporta. No caso de ficheiros CAD só 2 formatos são suportados – DXF e DGN. Está já pronto um novo driver para DXF e que lê também DWG, mas ainda não é incluído no QGIS (nem mesmo na versão 1.5 a lançar já em Julho).
O caso DXF
O OGR converte DXF para qualquer outro formato que suporte, como o shapefile. E mantém alguns atributos, como o layer, o que é muitas vezes suficiente para converter e organizar a informação CAD. Mas enquanto o QGIS não usar uma versão de OGR que inclua o driver DXF não vamos conseguir ler estes ficheiros directamente no QGIS. Temos assim de usar comandos de linha…
Assim, para evitar usar a linha de comandos do OGR, podemos fazer esta conversão no QGIS usando o plugin Dxf2Shapefile (incluído na instalação do QGIS). Mas surpreendentemente este plugin não mantém quaisquer atributos quando converte ficheiros DXF, e ficamos com pontos, linhas e polígonos sem sabermos o que representam. O que é muito desapontante. A sua utilização é muito fácil, mas os resultados são pobres dada a flagrante ausência de atributos.
Conversão de DXF para Shapefile no QGIS – perdem-se os atributos.
O caso DGN
Há uma outra opção – o QGIS lê directamente ficheiros DGN, e carrega-os para o mapa sem ser necessário uma conversão prévia. E melhor ainda, vários atributos são visíveis, e assim, tendo o ficheiro CAD no nosso mapa, podemos aplicar selecções de acordo com o level (equivalente ao layer dos DXF), e gravar para ficheiros shapefile.
O QGIS consegue ler DGN directamente e mantém atributos como o level, permitindo fazer selecções e gravar para shapefile.
Uma surpresa é que o DGN é carregado com todas as geometrias misturadas num só tema. O que é invulgar. Temos de nos habituar a esta ideia e encontrar forma de filtrar cada tipo de geometria para as conseguirmos separar e exportar para shapefile. Isto é, vamos criar um filtro (Query) no QGIS para ficar apenas com pontos, e exportá-los para um shapefile. E fazemos o mesmo depois para isolarmos as linhas e os polígonos.
Como o QGIS usa o OGR para ler ficheiros DGN, basta uma consulta à página do driver DGN do OGR, para ficarmos a saber quais os atributos a que temos acesso com ficheiros DGN. E vemos que o atributo “Type” indica o tipo de geometria: Line (3): Line geometry.
Line String (4): Multi segment line geometry.
Curve (11): Approximated as a line geometry.
B-Spline (21): Treated (inaccurately) as a line geometry.
Arc (16): Approximated as a line geometry.
Ellipse (15): Approximated as a line geometry.
Shape (6): Polygon geometry.
Text (17): Treated as a point geometry.
Ou seja, para no QGIS seleccionar todas as linhas num DGN, podemos usar a seguinte query (usando a opção “Query” no menu de contexto do tema DGN, acedido clicando com o botão direito sobre o tema DGN):
Type = 3 OR Type = 4 OR Type=11 OR Type = 21 OR Type = 16 OR Type = 15
No QGIS filtramos o DGN com uma query, para isolar um só tipo de geometria (ponto, linha ou polígono).
Depois de fazer a query todos os elementos que restam visíveis no QGIS serão linhas, e podem ser gravados para um shapefile usando a opção “Save as” do menu de contexto do tema.
Depois de termos a informação dividida por 3 shapefiles, um por tipo de geometria, podemos então fazer selecções por level para tentar isolar objectos com determinados significados.
Na verdade nem é preciso exportar para shapefile. Podemos simplesmente carregar o ficheiro DGN, filtrar as geometrias, e aplicar depois a simbologia que queremos. Será necessário converter quando, por exemplo, quisermos converter uma série de ficheiros DGN num único shapefile com toda a informação (ou para outro formato como PostGIS ou SpatiaLite).
O caso DWG
Este é o pior formato de informação geográfica do mundo. Ponto.
Além de ser alterado a cada 3 anos, é completamente fechado, isto é, para poder ler e escrever este formato é necessário pagar a terceiros, como a Autodesk ou a Open Design Alliance. A propósito da ODA e da má fama do DWG, podem ler esta novela espantosa relatada pelo 1º presidente desta ilustre fundação. Mas pode ser que as coisas estejam a mudar. Recentemente, a ODA chegou a acordo com a Autodesk e lá resolveram as disputas sobre marcas comerciais, e por coincidência (ou não) em Junho publicaram as especificações actualizadas que desenvolveram para ler e escrever DWG. É melhor aproveitar e fazer o download, não vá a situação alterar-se… Estas especificações têm sido insuficientes para criar programas que consigam escrever ficheiros DWG válidos, mas pelo menos para ler estes ficheiros já foram suficientes. Esta nova actualização não sei se virá alterar esta situação, mas terá nova informação sobre o formato DWG 2010…
Não vou alongar-me mais sobre o formato, interessa apenas frisar que até agora o software Open Source teve de criar bibliotecas para ler (ou escrever) ficheiros DWG fazendo um enorme esforço de “reverse engineering”. Que além de ser um trabalho muito pouco interessante, tem de ser revisto a cada 3 anos.
Assim, o QGIS não lê DWG. É possível que o venha a fazer no futuro próximo, havendo avanços no OGR nesse sentido. A ver vamos…
Mesmo a terminar este assunto, tenho de referir que o gvSIG lê DWG até à versão 2004…
Conclusão
Dadas as dificuldades actuais de interoperabilidade do formato DWG, este não é viável de momento com QGIS.
A opção DGN é muitíssimo funcional, e até muito fácil de trabalhar no QGIS. Para utilizadores de Microstation é óptimo. Para utilizadores de AutoCAD há a possibilidade de exportar para DGN a partir do AutoCAD 2008. Para os outros produtos baseados em DWG/DXF já não se pode dizer o mesmo.
Finalmente, o formato DXF é de momento uma má opção, a não ser que façamos a conversão pela linha de comando do OGR para shapefile ou semelhante. Mas espera-se em breve ter no QGIS um suporte ao nível do DGN. Mesmo assim, também obriga à exportação para DXF (a partir do formato CAD nativo), sendo um passo extra que é mais uma pedra na engrenagem para os técnicos CAD.
Se souberem de outras possibilidades aproveitem a secção de comentários.
Quando fica incumbido de publicar informação geográfica na web é quase sempre confrontado com esta questão – como publicar aquela colecção de ortos, composta por uma directoria cheia de ficheiros tif? (ou jpeg, ou ecw, ou sid…)
Este artigo nasceu num desses momentos, e da necessidade de determinar quais as opções existentes no MapServer, e saber qual delas é a melhor.
AVISO – artigo longo, com resultados de uma série de testes!!! Conclusões no final para os mais stressados…
Cenário inicial
Imaginemos um pequeno concelho que tem uma colecção de 45 ortofotomapas, em formato TIFF, não comprimido. Cada imagem ocupa 234MB, o que totaliza 10GB de imagens.
O objectivo é publicar estas imagens como uma cobertura que abrange o concelho, numa aplicação webgis, servida pelo MapServer.
A melhor opção
Para escolher a melhor forma de publicar as imagens é preciso saber o que é mais importante para nós: velocidade ou espaço em disco?
A verdade é que a compressão das imagens impõe uma penalização na velocidade com que os programas conseguem mostrar essas imagens. Essa penalização pode ser muito pequena ou muito grande, consoante o tipo de compressão e o tipo de imagem criada durante o processo de compressão. Geralmente, os ficheiros ECW e SID são extremamente comprimidos e relativamente rápidos. Em geral também, o formato JPEG2000 comprime muito as imagens mas é lento. O formato mais antigo JPEG é um compromisso entre os 2 grupos anteriores. Outra regra: assume-se que o MapServer é mais rápido com o formato TIFF, sem compressão, do que com formatos comprimidos, mas estas imagens ocupam muito mais espaço em disco.
Portanto, se a sua única preocupação é velocidade, e tem espaço em disco que não se importa de gastar com os seus ortofotomapas, em principio já sabe a sua resposta – use TIFFs sem compressão. Mas nada como verificar se esta “verdade” realmente se aplica aos seus dados em particular. Ahh, e não se esqueça de considerar o tráfego que vai gerar na rede se quiser usar os ortos em programas SIG desktop…
Temos ainda de saber como criar um layer em MapServer que use todas as imagens como um conjunto único. Afinal não quer que o utilizador seja obrigado a ligar 45 imagens uma-por-uma.
Para iniciar os testes converteram-se todas as imagens para os diversos formatos. Os tamanhos totais em cada formato ficaram assim:
Formato
Dimensão
TIF+overheads
13,5 GB
JPG+overheads
915 MB
ECW
605 MB
JP2
509 MB
Os tamanhos indicados incluem imagens de resolução reduzida, chamadas overheads ou pirâmides. Mais sobre isto adiante…
Para ver os comandos de conversão do GDAL para cada formato pode consultar este artigo anterior – GDAL: Formatos comprimidos.
Usar mosaicos em MapServer
Um mosaico de imagens em MapServer é um layer do tipo RASTER que aponta para um conjunto de imagens em vez de uma só.
A forma tradicional de referenciar um mosaico é criando um shapefile que contém um quadriculado com as extensões das imagens. Este shapefile é criado com um comando do GDAL chamado gdaltindex.
Mas há uma nova opção. Podemos usar o formato VRT, um formato virtual que é constituído por um ficheiro de texto que indica a fonte dos dados e a forma como são organizados. Um ficheiro VRT pode listar um conjunto de imagens de forma a que o MapServer e outras aplicações o leiam como uma imagem única, quando na verdade será composto por todas as nossas imagens. O comando para criar um mosaico VRT é o gdalbuildvrt.
Por último, temos a opção de força bruta: juntar todas as imagens numa só, criando uma imagem enorme em disco que abrange toda a nossa área de interesse. Ou seja, no nosso caso em estudo esta imagem teria 10GB. Para criar este mosaico monolítico usamos o comando gdal_merge.
Vamos ao longo do artigo analisar cada opção e no final medir os tempos que o MapServer demora a visualizar cada tipo de mosaico.
Mosaico VRT
O GDAL suporta um formato virtual, VRT, que lista ficheiros já existentes e os descreve como um todo. Podemos agregar várias imagens numa só, definir um novo sistema de coordenadas, ou no caso de ficheiros vectoriais definir filtros de atributos, e renomear atributos, tudo sem alterar os ficheiros originais. Os ficheiros VRT são ficheiros de texto em formato XML e podem ser editados manualmente, ou criados com o gdal_translate ou com o comando gdalbuildvrt. Mais info aqui.
Para construir um mosaico a partir das imagens numa directoria, basta usar o seguinte comando:
gdalbuildvrt mosaico_tif.vrt directoria\*.tif
O ficheiro “mosaico_tif.vrt” é criado com o seguinte conteúdo:
O QGIS 1.4.0 consegue ler este tipo de ficheiro, mostrando-o como uma só imagem:
Mosaico VRT visualizado no Quantum GIS 1.4.0.
Mas a performance é um problema. Para visualizar este mosaico, o QGIS tem de abrir as 45 imagens, ler todos os pixels, e mostrá-los. Ainda por cima, nesta escala a maior parte da informação é inútil porque não se distinguem todos os pixels. Para resolver este problema, criam-se overheads…
Criar Overheads
Os ficheiro TIFF originais têm 234MB cada um, e para visualizar todos os ortos o QGIS tem de ler todas as imagens, num total de 9GB, e mostrá-las numa escala onde o todo pormenor se perde. Este problema aplica-se a todos os programas SIG, incluindo o MapServer.
Para evitar este desperdício de tempo, criam-se overheads ou pirâmides, que são imagens de resolução decrescente gravadas num só ficheiro com extensão OVR. Assim, para uma escala pequena, como a do exemplo anterior, o QGIS tem apenas de ler e mostrar a imagem de pior resolução, já que se ajusta bem ao pormenor visível a essa escala. Consoante o utilizador faz “zoom in”, o QGIS selecciona a imagem com a resolução apropriada a essa escala, até que a partir de uma dada escala começa a mostrar a imagem original. Mas neste momento já só é necessário ler uma pequena porção da imagem para cobrir a área visível. E assim se acelera a visualização das imagens.
Para criar overheads usamos o comando do GDAL, gdaladdo:
O parâmetro “-ro” indica que a imagem original não deve ser alterada, e portanto as overheads serão criadas num ficheiro separado, que terá a extensão OVR.
Os números depois do nome da imagem são os níveis a criar com resolução reduzida. O n.º 2 indica metade da resolução original, 4 é 1/4 e assim sucessivamente. Até que nível de redução calculamos depende da extensão geográfica das imagens e da sua resolução original. Uma forma fácil de determinar até que redução devemos chegar é consultar o QGIS…
O QGIS consegue agora criar overheads – acedendo às propriedades de um tema de imagem, na secção de Pyramids existe um botão para criar pirâmides (embora seja mais lento que o comando GDAL). Aqui o QGIS mostra a lista de resoluções que aconselha – é só contar quantos níveis são aconselhados pelo QGIS. Na imagem seguinte, podemos ver o QGIS a criar pirâmides para uma das imagens:
Construir pirâmides/overheads no Quantum GIS 1.4.0.
Como o QGIS indicava 7 níveis de pirâmides para as minhas imagens, foi o que usei no comando: 2, 4, 8, 16, 32, 64, 128 = 7 níveis.
Criei então overheads para o mosaico VRT. O resultado foi um ficheiro OVR com 776MB, ou seja, 33% do tamanho original. Esta é a taxa comum na criação de overheads e temos de prever este consumo adicional de disco.
Para testar as overheads, carreguei de novo o mosaico VRT no QGIS. Agora a imagem total foi mostrada quase instantaneamente. Mas ao fazer zoom in a velocidade degradou-se. Significa que o QGIS deixa de usar as pirâmides do VRT e passa a mostrar as imagens originais… penso que poderá ser um bug.
Portanto a solução passa por criar overheads para cada uma das imagens originais, e ver se assim o QGIS utiliza sempre as overheads.
Para isso usei um comando de linha que percorre todas as imagens TIFF numa directoria e executa o comando gdaladdo:
for %I in (directoria_originais\*.tif) do gdaladdo -ro %I 2 4 8 16 32 64 128
O resultado foi a criação de um ficheiro OVR para cada TIFF, cada um com 82MB (35% dos originais). Voltando a carregar o mosaico VRT no QGIS, o desempenho foi excelente em todos os níveis de zoom, provando que o QGIS usou sempre as overheads.
NOTA: por curiosidade abri o mosaico VRT no ArcGIS, e tudo funcionou perfeitamente, incluindo as overheads! Sabe-se há muito que o ArcGIS incluía o GDAL, não se sabendo bem para o quê. Pelos vistos, servirá também para ler VRT’s e overheads.
O caso ECW
O formato ECW agrada-me muito. Tem compressões equivalentes ao MrSID, é gratuito para comprimir imagens até 500MB, é rápido a visualizar, e já inclui pirâmides no próprio ficheiro. Poupa assim espaço em disco 2x: na compressão e nas pirâmides.
A questão que se coloca é saber até que ponto vai a penalização na performance do MapServer ao ter que descomprimir os ECW para os visualizar a cada Zoom e a cada Pan.
Para criar um mosaico VRT com ECW’s tivemos de converter todos os TIFF originais, com o seguinte comando:
for %I in (directoria_originais\*.tif) do gdal_translate -of ECW -co TARGET=90 %I directoria_destino\%~nI.ecw
As imagens originais passaram de 13GB (contando com as overheads) para 605MB – poupando 95% do espaço! Podiamos ainda comprimir mais, mas neste estudo preferi manter os defaults…
Criámos um novo VRT com as imagens ECW, e testámos no QGIS. A visualização foi muito rápida e sem degradação ao aumentar a escala.
O caso JPEG
Este formato é muito apreciado por ser familiar, bastante rápido, e apresentar taxas de compressão bastante atractivas (embora não consiga acompanhar a compressão dos novos formatos como MrSID e ECW). A questão que se coloca é saber se a multa devida pela descompressão se nota ou não em MapServer. Não esquecer que será necessário criar overheads. Neste teste optei por criar as pirâmides também em formato JPEG, por forma a ser mais fiel ao formato. Se este formato for suficientemente rápido poderá ser uma boa alternativa ao TIFF. Para criar pirâmides em formato JPEG pode-se usar o seguinte comando (está tudo documentado na página do gdaladdo):
O resultado foram imagens JPEG e OVR ocupando 915MB (93% de compressão). Em QGIS o resultado foi mais uma vez excelente… visualização rápida de inicio, sem degradação com os zoom in… Além da velocidade, fiquei surpreendido com a compressão atingida e com a óptima qualidade das imagens ao ver todo o mosaico.
O caso JPEG2000
Este formato é uma alternativa aos formatos ECW e MrSID, mas mais aberto. No entanto, tem-se revelado sistematicamente lento demais para o poder utilizar a não ser para fins de arquivo.
Decidi mesmo assim inclui-lo no teste. Converti todas as imagens TIFF para JP2, e criei um mosaico VRT. No teste com QGIS, a velocidade foi muito rápida de início, apenas demorando um pouco mais com o aumento da escala de visualização. No entanto, a sua qualidade de imagem ao ver todo o mosaico foi excelente.
Mosaicos Shapefile (TILEINDEX)
A forma tradicional de usar mosaicos no MapServer é criar um shapefile com polígonos que cobrem a área de cada ortofotomapa. Este shapefile é depois referenciado no mapfile em vez do ficheiro VRT.
A questão que se coloca é saber se a utilização de um VRT implica uma redução de performance, quando comparada com a utilização de um shapefile.
Criei por isso mosaicos usando shapefiles, e medi os tempos de visualização em MapServer. Afinal, nem sempre novos métodos se revelam melhores que os antigos. O comando que usei foi o seguinte:
gdaltindex mosaico.shp directoria\*.tif
Não descobri forma de visualizar este tipo de mosaico em QGIS…
Mosaicos monolíticos
A última variante de mosaicos conhecida pela humanidade – juntar todas as imagens numa única, e gigante, imagem.
Para criar este mosaico vamos usar a ferramenta gdal_merge, que é um script python incluído no GDAL (pelo menos na versão FWTools). O plano é juntar todos os tiffs originais, criando um novo tiff. Mas nesta altura, o espaço em disco começava a escassear…
Para poupar algum espaço em disco, optei por usar compressão JPEG. Como o ficheiro poderá ser maior que 4GB usei a opção “bigtiff=yes” (por limitações do formato tiff). E como o ficheiro cobrirá uma grande extensão geográfica, para acelerar o acesso a pequenas áreas, usei também a opção “tiled=yes”. Assim, o comando para criar o mosaico foi o seguinte:
Isto produziu um ficheiro com 3,5GB, dada a compressão JPEG dentro do ficheiro TIFF. Confuso? Sucede que o formato TIFF suporta uma variedade de processos de compressão. Um deles é o JPEG. Claro que esta compressão poderá comprometer a velocidade do mosaico, mas não tinha mais espaço em disco para criar um mosaico sem compressão.
O passo seguinte foi criar overheads/pirâmides para este mosaico. Também aqui optei por criar pirâmides comprimidas em JPEG, usando o seguinte comando:
Este comando criou um ficheiro OVR com 320MB, sendo apenas 9% do original devido à compressão usada. No total, a compressão foi de 72%. Nada mau…
Em QGIS este mosaico foi extremamente rápido, mostrando o ficheiro numa fracção de segundo, e zooms e pans foram também muito rápidos. Definitivamente, foi das melhores prestações senão a melhor.
NOTA: seria interessante criar um mosaico enorme ECW, mas não foi possível por causa do limite de 500MB imposto pela licença gratuita do compressor ECW (incluído no GDAL).
E agora… com MapServer
Todos os testes foram efectuados num portátil, com Windows 7, 32-bit, 2 GB de memória, e MS4W 2.2.7 (inclui o MapServer 5.0.2). Portanto, podemos esperar melhores resultados num PC ou servidor, onde o disco rígido será em princípio bastante mais rápido. Os testes foram feitos com uma pequena aplicação OpenLayers, que inicia com um mosaico visível em toda a extensão, sendo depois feitos 4 zooms no centro do mapa, manualmente.
Os tempos foram obtidos no log produzido pelo MapServer. Para criar este log, inseriram-se as seguintes linhas no mapfile:
O mapa foi configurado para gerar imagens em JPEG, através do AGG, usando esta secção no mapfile:
OUTPUTFORMAT
NAME jpg
DRIVER AGG/JPEG
IMAGEMODE RGB
END
Para definir um layer com um mosaico VRT usou-se a seguinte sintaxe no mapfile, indicando o ficheiro VRT no tag DATA:
LAYER
NAME 'mosaicoTotal_tif'
TYPE RASTER
DUMP true
TEMPLATE fooOnlyForWMSGetFeatureInfo
EXTENT -16500.000000 -83122.641509 4500.000000 -66877.358491
DATA 'mosaicoTotal_tifoverhds.vrt'
METADATA
'ows_title' 'mosaicoTotal_tif'
END
STATUS OFF
TRANSPARENCY 100
PROJECTION
'init=EPSG:27492'
END
END
Note-se que foram criados vários layers deste tipo, havendo um VRT para cada tipo de imagem: TIFF, ECW, JPG, JP2.
Para os mosaicos baseados em shapefile usou-se a seguinte sintaxe (TILEINDEX e TILEITEM no lugar de DATA):
LAYER
NAME 'mosaicoTotalshp_tif'
TYPE RASTER
DUMP true
TEMPLATE fooOnlyForWMSGetFeatureInfo
EXTENT -16500.000000 -83122.641509 4500.000000 -66877.358491
TILEINDEX 'mosaicoshp_tif.shp'
TILEITEM 'location'
METADATA
'ows_title' 'mosaicoTotalshp_tif'
END
STATUS OFF
TRANSPARENCY 100
PROJECTION
'init=EPSG:27492'
END
END
Resultados do MapServer
Usando mosaicos VRT obtiveram-se os seguintes tempos:
Zoom
TIFF+overhds
ECW
JP2
JPG
TIFmonolítico
Inicial
0.298
0.744
1.108
0.81
0.094
Z1
0.354
0.609
3.205
0.945
0.259
Z2
0.419
0.761
3.173
1.018
0.291
Z3
0.415
0.709
3.053
1
0.284
Z4
0.65
0.658
2.533
0.966
0.276
Totais
2.136
3.481
13.072
4.739
1.204
Espaço disco
13,5GB
605MB
509MB
915MB
3,85GB*
*usando compressão JPEG, e incluindo overheads.
E em gráfico (a última categoria “Totais” representa a soma de todos os zooms, evidenciando os ganhos acumulados nos formatos mais rápidos):
Desempenho de mosaicos VRT em MapServer.
E o vencedor é… o mosaico monolítico, destacadíssimo. Dos mosaicos VRT, o mais rápido foi o mosaico de TIFF’s não comprimidos, como se supunha de início, com o formato ECW em 2º lugar, bastante melhor que o JPEG em 3º. O formato JPEG2000 é completamente desaconselhado.
Usando mosaicos baseados em Shapefile, obtiveram-se os seguintes resultados:
Zoom
TIFF+overhds
ECW
JP2
JPG
TIFmonolítico
Inicial
0.287
2.374
4.206
2.366
0.094
Z1
0.337
2.355
6.121
2.355
0.259
Z2
0.247
1.082
3.583
1.139
0.291
Z3
0.186
0.656
3.069
0.76
0.284
Z4
0.176
0.657
2.412
0.926
0.276
Totais
1.233
7.124
19.391
7.546
1.204
Espaço disco
13,5GB
605MB
509MB
915MB
3,85GB*
*usando compressão JPEG, e incluindo overheads.
E em gráfico:
Desempenho de mosaicos SHP em MapServer
E o vencedor é… de novo o TIFF monolítico, mas havendo várias alterações. Só o mosaico de TIFF’s não comprimidos melhorou o desempenho em quase 100%, reduzindo de 2,1s para 1,2s. Todos os outros pioraram bastante, por vezes duplicando o tempo de visualização. Não encontrei explicação para esta penalização. O shapefile continha apenas 45 polígonos, sendo difícil acreditar que possa causar tão grande penalização, mesmo considerando que o MapServer tem de determinar quais os polígonos visíveis num momento, determinar as áreas de cada um, e abrir as imagens correspondentes… parece-me pouco trabalho para explicar diferenças de 1,6s como no caso dos ECW… Mas factos são factos.
Conclusões
Se não existirem impedimentos, deverá unir as suas imagens num mosaico único, em formato TIFF, comprimido em JPEG, e criar pirâmides também com compressão JPEG. Obtém o maior desempenho possível e com o extra de poupar 70% do espaço em disco. Esta abordagem foi simplesmente a melhor… mais vale guardar os seus originais num arquivo.
Quanto aos mosaicos VRT mostraram ser uma boa opção. Quase todos os formatos tiveram melhor desempenho quando usados através deste formato virtual, do que usando um mosaico baseado em shapefile. A excepção foi o mosaico de TIFF’s não comprimidos. Aqui, usar o mosaico shapefile foi melhor, muito melhor.
Nota Final
O formato VRT não serve apenas para criar mosaicos sem alterar as imagens originais, e por isso poderá ser uma opção atractiva em certas situações. Podemos, por exemplo, definir uma deslocação de +200km, +300km sem andar a editar ficheiros de coordenadas – alguém se lembra de passar por isto?? Parece-me que sim.
Cábula de Comandos
Todos os comandos usados no artigo…
Criar mosaico VRT a com imagens de uma directoria:
gdalbuildvrt mosaico_tif.vrt directoria\*.tif
Criar overheads/pirâmides de uma imagem, num ficheiro separado
gdaladdo -ro imagem.tif 2 4 8 16 32 64 128
Criar overheads/pirâmides para todas as imagens TIFF numa directoria
for %I in (directoria_originais\*.tif) do gdaladdo -ro %I 2 4 8 16 32 64 128
Converter todos os TIFF numa directoria para ECW noutra directoria
for %I in (directoria_originais\*.tif) do gdal_translate -of ECW -co TARGET=90 %I directoria_destino\%~nI.ecw
Tempo de leitura: 5minEsta é a parte 3 desta série, sobre a utilização de PostGIS com ArcGIS, que aborda a estruturação da bd PostGIS. Os artigos anteriores são:
Depois de instalar o PostgreSQL+PostGIS+ArcSDE, e configurar o formato de armazenar os nossos dados na bd, para que usemos as geometrias nativas do Pg em vez dos objectos ESRI (para compatibilidade com software Open Source), teremos de definir que utilizadores vamos criar na bd, e a forma como organizamos os dados.
Bases de Dados e Utilizadores
A organização interna do PostgreSQL é algo semelhante à do SQL Server, e bastante diferente do Oracle. Por exemplo, um servidor PostgreSQL contém várias bases de dados, ao contrário do Oracle onde uma bd corresponde a um serviço ou instância. Se quisermos mais bd’s temos de criar novas instâncias, com configuração independente, conexões, dados, utilizadores, etc.
Durante a instalação do PostGIS é instalada uma bd chamada “postgis”, e podemos usá-la para armazenar os nossos dados geográficos ou podemos criar outras bd’s ao nosso gosto…
Podemos assim guardar a informação geográfica na base de dados postgis que é criada durante a instalação do PostGIS. Ultrapassada esta decisão, temos de criar e configurar os utilizadores que vamos usar para carregar a nossa informação, evitando usar os utilizadores de sistema, criados durante a instalação, que são o “postgres” e o “sde” (utilizador criado pela instalação do ArcSDE e que serve para efectuar a sua gestão). A criação de novos utilizadores é muito recomendado e geralmente é omitido nos tutoriais e instruções de instalação…
Pessoalmente, prefiro configurações com poucos utilizadores, criando apenas 1 login para cada uso: os utilizadores do SIG usam o mesmo login para a visualização, e um outro para a gestão dos dados (criação, edição, eliminação de layers, metadados, etc.). Aplicações webgis podem partilhar também um único login para acesso aos dados. A abordagem oposta é a de criar um login por utilizador, ou usar a autenticação integrada do Windows (em que as contas de utilizador de domínio são também usadas na bd). Esta é uma decisão que se repercutirá mais tarde na manutenção e monitorização da actividade da bd. Se começarmos com a abordagem mais simples (poucos logins), podemos mais tarde introduzir o esquema de autenticação por utilizador do SIG.
Uma das razões apontada para usar o esquema de mais utilizadores, é que podemos controlar exactamente quem está ligado, ou mesmo até saber quem editou os dados numa dada altura. E esta é uma argumentação válida. Mas a abordagem mais simplista, de poucos logins, também permite algum controlo, uma vez podemos ver no servidor a listagem de conexões activas, e estas são descritas não só pelo login usado, mas também pelo nome da máquina de onde são efectuadas. Como em geral, uma máquina pertence a um utilizador, acabamos por saber que utilizador “real” está efectivamente ligado à bd.
Utilizadores e Schemas
Outra questão a considerar é a de quantos “schemas” serão criados na bd. Um schema é um agrupamento de objectos na bd ao qual se atribui um nome; o nome dos objectos apenas se podem repetir em schemas diferentes. Por exemplo, podemos ter schemas com o nome “Ambiente” com os dados desta temática, ou “Cadastro”, e por aí fora. É preciso sublinhar que podemos controlar quem tem acesso a um schema, podendo proibir o acesso a certos utilizadores, dar acesso apenas de leitura, ou por fim, dar controle completo.
Quando possível, prefiro usar o schema “public” criado de raiz durante a instalação do PgSQL, e não criar mais schemas. Esta abordagem é muito simples, e tem a vantagem de ser a mais compatível com o software que interage com o PostGIS (já aconteceu usar software que não via outros schemas além do public), além de simplificar a gestão de privilégios (o que também pode ser limitativo, caso as nossas necessidades exijam compartilhar os dados por áreas de edição).
Mas sucede que o ArcSDE necessita que todos os utilizadores que criam dados tenham o seu próprio schema. Pelo que a centralização dos dados geográficos no schema public não é possível. Temos de ter tantos schemas quantos os utilizadores que criam dados. Ou seja, se o utilizador João for alguém que tem de criar tabelas novas na bd, então terá de ter obrigatoriamente o seu próprio schema, e com o mesmo nome “João”!
A questão não é complicada se tivermos poucos criadores de dados, porque teremos de criar poucos schemas. Isto não impede que haja muitos editores, que podem editar dados de outros utilizadores e por isso não precisam de ter o seu próprio schema.
Para criar utilizadores no PostgreSQL usamos o PgAdmin (programa de administração) para criar “login roles“. Podemos também criar perfis que no PgSQL são denominados “group roles“, e que permitem gerir conjuntos de utilizadores em simultâneo, que partilham privilégios. O ArcSDE necessita que certas regras sejam seguidas na criação de utilizadores, se quisermos usar o ArcGIS para criar, editar e visualizar os dados.
Em resumo, para criar um novo utilizador que pode criar novos dados através do ArcGIS/ArcSDE, vamos:
i) criar um schema com o mesmo nome do novo utilizador; e
ii) criar um novo login na base de dados postgis, chamado por exemplo “gestorsig”. (Podemos usar o PgAdmin, mas aconselho usar a janela de sql para criar o utilizador.)
O utilizador deverá ter privilégios totais no seu próprio schema, mas também o privilégio de “usage” sobre o schema “sde”, onde são colocadas as tabelas de sistema do ArcSDE. Isto é necessário porque quando o utilizador cria uma nova tabela tem de a registar numa série de tabelas de sistema. Claro que isto é feito automaticamente pelo par ArcSDE/ArcGIS, mas se o utilizador não tiver privilégios não será possível.
Por outro lado, o utilizador “sde” precisa de ter acesso às tabelas criadas, sendo por isso necessário atribuir-lhe o privilégio “usage” sobre o schema do novo utilizador, para que seja capaz de efectuar algumas operações de manutenção (limpeza do versionamento).
E ainda um passo final – como optámos por armazenar os nossos vectores usando o tipo espacial nativo do PostGIS, o nosso utilizador necessita de acesso de escrita à tabela “public.geometry_columns”, onde se registam todas as tabelas espaciais do PostGIS. De outra forma, as nossas tabelas não seriam reconhecidas como tendo geometrias.
Concluindo, para criar um utilizador capaz de criar novas tabelas, usamos o seguinte SQL:
Update (13/06/2010): é também necessário dar pelo menos acesso (SELECT) à tabela de sistemas de coordenadas (spatial_ref_sys).
create role gestorsig login password 'PasswordDoUtilizador' noinherit createdb;
create schema gestorsig authorization gestorsig;
grant usage on schema sde to gestorsig;
grant usage on schema gestorsig to public;
grant select, insert, update, delete on table public.geometry_columns to gestorsig;
grant select on table public.spatial_ref_sys to gestorsig;
Neste código há uma pequena nuance: damos acesso ao nosso schema a todos os outros utilizadores (“…to public”), e assim não nos preocupamos se damos acesso a A ou B.
Para criar um utilizador que edita dados, mas não cria novas tabelas, o processo é quase igual. Apenas não necessita do seu próprio schema (usará o public por default):
create role editorsig login password 'PasswordDoUtilizador';
grant usage on schema sde to editorsig;
grant select, insert, update, delete on table public.geometry_columns TO editorsig;
Nota: como o nosso utilizador que cria dados (gestorsig) deu acesso a todos os utilizadores, não temos de o fazer explicitamente para novos utilizadores.
Nota 2: para podermos editar os dados criados pelo gestorsig, temos de dar privilégios de UPDATE ao nosso editor. Podemos fazê-lo usando o ArcCatalog (selecionar as Feature Classes, e com botão direito usar a opção “Privileges”), ou usando SQL.
No caso de utilizadores que só visualizam dados, o processo é igual. A diferença é que no ArcCatalog apenas damos o privilégio de SELECT sobre os objectos criados.
Deixo aqui 2 links que resumem a forma de criar novos utilizadores:
Todo este processo é muito semelhante ao que se passa com outros SGBDR’s, como Oracle ou SQL Server. Apenas muda a terminologia, e alguma da lógica de compartimentação da estrutura da bd. Para quem vem do mundo Oracle, a adaptação ao PostgreSQL é muito fácil, e para utilizadores de SQL Server não é muito diferente…
Tempo de leitura: 4minEste post é o 2º sobre integrar ArcGIS e PgSQL. A 1ª parte pode ser encontrada aqui.
Este artigo continua a experiência de usar o PgSQL como base de um SIG baseado em ArcSDE/ArcGIS, debruçando-se sobre a instalação e tipo de conexões. Não é uma introdução ao PostgreSQL/PostGIS, e é assumido que o leitor tem algum conhecimento prévio ou que o irá obter noutra fonte… por exemplo aqui:
Workshop PostGIS do Fred Lehodey/Ricardo Sena, das 1as Jornadas SIG Aberto em Águeda – Workshops PostGIS
Instalação do ArcSDE+PostgreSQL+PostGIS
O instalador do ArcSDE é muito simples, e até inclui o PostgreSQL. Mas se seguirmos o wizard de instalação do ArcSDE, não será instalado o PostGIS e o ArcSDE será instalado no seu modo default, com o seu próprio tipo espacial (coluna de geometria) e o seu próprio SQL espacial. Desta forma, só se consegue aceder aos dados geográficos com software ESRI.
Para instalar o ArcSDE de forma a que os dados sejam armazenados usando o tipo espacial do PostGIS é necessário desviarmo-nos um pouco do caminho seguido pelo wizard de instalação. Quando o wizard acaba de instalar o PostgreSQL, temos de parar, e instalar o PostGIS, antes de prosseguir com o wizard do ArcSDE. Tudo é bem explicado neste artigo da ESRI:
No final da instalação ficamos assim com o PostgreSQL, o PostGIS, e o componente ArcSDE.
O componente ArcSDE cria uma base de dados no PostgreSQL, chamada “sde”, e um utilizador próprio chamado “sde”. É nesta bd que ficam as tabelas de sistema do ArcSDE e a suas próprias funções, triggers, etc.
O nosso servidor PostgreSQL fica também com a estrutura habitual do PostGIS, havendo uma bd denominada “postgis”. Nesta bd também são instalados objectos do ArcSDE, como tabelas de configuração da geodatabase que mantém registo dos objectos que são criados através de software ESRI e que compõem o modelo de dados da geodatabase.
Na instalação há um problema com privilégios – a instalação do ArcSDE pára porque não consegue escrever nas directorias do PostgreSQL (“lib” e “bin”). Para resolver basta usar o explorador do Windows para adicionar o privilégio de escrita nessas pastas ao nosso utilizador (que estamos a usar ao executar o instalador do ArcSDE). Se usarmos o utilizador “Administrator” o problema não surge.
Outra nota importante é que o PostgreSQL é instalado com as definições pré-definidas. Sucede que estas definições são à prova de equipamento pré-histórico… ou seja, o PostgreSQL instalado e sem alterações funciona até num Intel 486 com 256MB de memória. Mas claro que a performance não é a desejada e deve-se editar as configurações. Noutro artigo espero discutir um pouco as opções mais comuns a alterar.
A título de curiosidade, os valores default de configuração ocupam cerca de 60MB de memória (sem iniciar o serviço SDE e sem contar com o pg_ctl.exe).
Tipo de Ligações ArcSDE
Depois da instalação são criados 2 novos serviços no Windows: o usual do PgSQL, e um próprio do ArcSDE.
O serviço do ArcSDE é o gestor de conexões do ArcSDE. Ou seja, as aplicações da ESRI ligam-se a este serviço, que depois inicia as conexões à base de dados para cada aplicação. A ESRI designa este esquema conexões como “Application Server connections” ou de 3 camadas (3-tier). Cada utilizador de ArcGIS que se liga deste modo vai criar um processo no servidor chamado “gsrvr.exe”, que optimiza a comunicação dos dados entre a bd e o ArcGIS. Cada um destes processos ocupa entre 15MB e 100MB de memória, para além da memória ocupada pelo próprioPgSQL. Se houver 10 postos ArcGIS, serão lançados 10 processos destes no servidor, ocupando 150-1000MB de memória. Isto para além dos processos que o PgSQL irá criar por si.
Nos últimos anos, a ESRI tem vindo a incentivar o uso de outro tipo de conexões – conexões directas.
Nas conexões directas não é necessário usar o serviço ArcSDE, o ArcGIS liga-se directamente à bd. Isto é possível porque o ArcGIS passou a incluir as dll’s do ArcSDE, e assim a memória que era ocupada no servidor passa a ser consumida no PC com o ArcGIS. O inconveniente é que estas conexões ocupam um pouco mais a rede, mas teoricamente não há impacto perceptível. Com as conexões directas apenas temos de contar com os processos do próprio PgSQL.
Naturalmente, desde que a rede não esteja congestionada, é preferível usar conexões directas. No entanto, o esquema de conexões 3-níveis permite separar o ArcSDE da bd, o que possibilita a utilização de clusters, beneficiando da distribuição de carga que este tipo de sistemas oferece.
Conexões PgSQL
O PgSQL quando inicia cria um conjunto de 6 processos em memória no servidor. Em Windows, todos estes processos se chamam “postgres.exe”. Um destes processos é o processo principal do servidor que mantém a cache de dados e outras informação que persistem entre conexões. A configuração do PgSQL influenciará principalmente este processo, que tanto pode ocupar 26MB como 500MB, ou mais.
Por cada cliente que se conecta (QGIS, gvSIG, …), o PgSQL cria mais 1 processo na memória do servidor, correspondendo a essa conexão (curiosamente, no caso do ArcGIS são sempre criados 2 processos postgres.exe). Este processo ocupará memória consoante as definições do PgSQL, dependendo fortemente do tipo de operações executadas pelo cliente. Assim, uma pesquisa simples consumirá pouca memória, mas a visualização de um layer com 120.000 registos já ocupará +200MB. O caso de maior carga que encontrei foram operações de carregamento de informação em massa ocupando 500MB de memória ou mais.
Confesso que não estou habituado a esta flutuação no consumo de memória. Ao usar Oracle, temos uma certa rigidez no consumo de memória, que orbitará em redor dos parâmetros determinados pelo gestor. Se o Oracle der sinal de necessitar de mais memória, é o gestor que tem de redefinir os parâmetros permitindo que o Oracle consuma mais memória.
No caso do PgSQL, a memória ocupada é também reflexo da configuração definida pelo gestor, mas a variação da memória ocupada é muitíssimo maior. E varia por cada utilizador que se liga, e pelas operações que irá efectuar. É um dimensionamento mais difícil de manter dentro dos limites do servidor.
Suponho que é uma questão de habituação ao processo. Durante uma fase inicial de implementação será necessário monitorizar de perto a utilização de memória no servidor, e adaptar as configurações do PgSQL. Tal e qual como se passa com outros servidores SGDB. Penso ainda regressar a este assunto, continuando esta série de artigos… até breve.
Tempo de leitura: 4minOlá a todos. Desde o meu último post passou mais tempo do que gostaria… mas hoje consegui “empurrar” este post.
A questão que trago aqui hoje é uma forma de integrar um SIG baseado em software ESRI com software Autodesk. Ou seja, se a sua organização usa ArcGIS Server então saiba que pode fazer chegar toda a sua informação SIG aos utilizadores de AutoCAD/Map/Civil, e tudo sem conversões ou múltiplos ficheiros. Melhor, pode visualizar toda a informação publicada pela ESRI no site ArcGIS Online no AutoCAD, e isso inclui os ortofotomapas do IGP, de 2004 e com 1 m de resolução.
A solução é o plugin da ESRI “ArcGIS for AutoCAD”, para AutoCAD (como o nome indica). É um download gratuito que está no site da ESRI. Depois de instalado vai acrescentar um menu e uma ribbon ao AutoCAD chamados “ArcGIS” e que permitem definir ligações a serviços ArcGIS Server, localizados na Intranet ou na Internet, o que abre uma grande via de comunicação entre o mundo SIG e o mundo CAD. Este plugin oferece ainda uma nova forma de produzir informação CAD (no AutoCAD) com atributos denominada “Mapping Specification for Drawings” e que, de acordo com a ESRI Inc., é mais interoperável – não obriga a conversões complexas, evita perda de informação quer no lado SIG quer no lado CAD, e é baseado apenas em ficheiros DWG “normais”. Pode obter mais informação aqui: Mapping Specification for Drawings. Ainda não tive a oportunidade de investigar em detalhe esta nova opção… mas este video da ESRI ilustra o processo.
Mas regressemos ao tópico principal – como ver no AutoCAD informação publicada através do ArcGIS Server?
Instalação do ArcGIS for AutoCAD
A instalação segue o processo normal: depois de fazer o download, basta executar o ficheiro obtido. Nos casos que observei, os novos elementos na interface do AutoCAD não foram correctamente adicionados, pelo que foi necessário fazê-lo manualmente. Para isso bastou executar o comando “cuiload” (dentro do AutoCAD) e na janela que abre indicar o ficheiro “C:\Program Files\ArcGIS for AutoCAD\ afaUI.cui” (ou equivalente de acordo com a pasta de instalação).
A partir daqui, o menu e a ribbon ArcGIS ficarão visíveis.
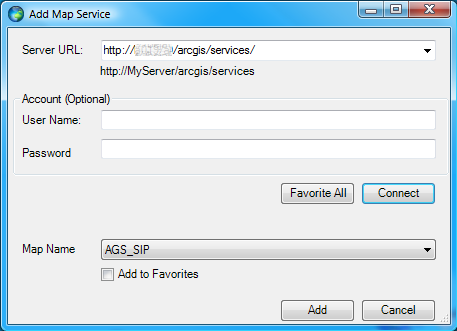
Adicionar um serviço
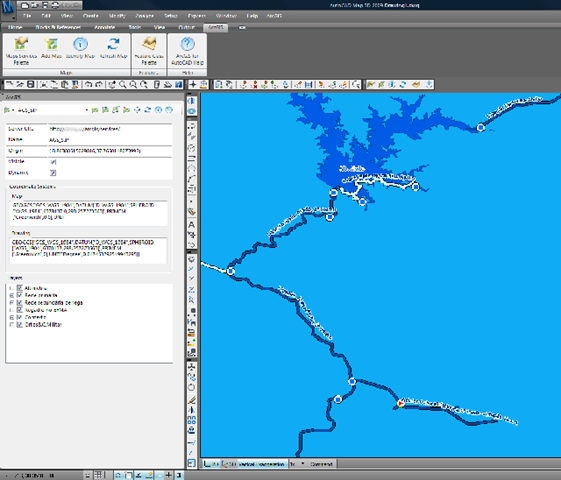
Para adicionar um serviço ArcGIS, basta usar o botão “Add Map”, e preencher os dados do endereço do servidor, e nome do serviço pretendido. Na imagem seguinte é mostrada a ligação a um servidor interno na EDIA com um serviço que mostra as infra-estruturas do EFMA, usando dados ArcSDE e simbologia ArcMAP:
E o resultado depois de aproximar a uma área com dados é (desculpem a qualidade da imagem):
Podem ser usados serviços dinâmicos e de cache (em que as imagens são previamente geradas para uma quadrícula e para um conjunto de escalas pré-definidos). Os serviços de cache permitem uma velocidade de interacção muito maior, com a contra-partida de existir alguma desactualização dos dados.
Adicionar o serviço ArcGIS Online com os ortos do IGP
No momento em que fiz este artigo, o AutoCAD não reconheceu o proxy da empresa (que exige autenticação), pelo que não pude capturar imagens… não foi possível determinar se o problema é do AutoCAD ou se é do plugin.
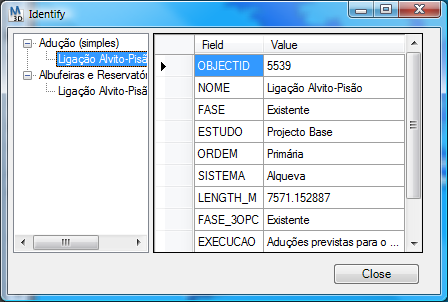
Identificar vectores num serviço ArcGIS Server
O plugin também inclui uma ferramenta de “Identify” que permite consultar os atributos da informação publicada. Por exemplo, identificar um canal no serviço da EDIA daria o seguinte resultado:
Conclusões
Esta ferramenta é realmente um passo em frente na interligação SIG-CAD, ou melhor, ESRI-Autodesk. Embora o AutoCAD Map e Civil tenham a capacidade de ligação a serviços WMS, a verdade é que a minha experiência com essa funcionalidade não tem sido a melhor (muitas vezes o mapa não redesenha o serviço WMS, e a impressão não refresca a imagem para ajustar ao tamanho do layout). Por outro lado, a ligação a serviços ESRI em cache é agora possível, o que traz as 2 grandes vantagens destes serviços: 1) são muito mais rápidos; e 2) exigem muito menos esforço por parte do servidor SIG, o que permite servir mais utilizadores com o mesmo servidor.
Neste momento, este plugin está em utilização na EDIA principalmente para visualizar, em AutoCAD, os mosaicos de ortofotomapas residentes em ArcSDE, algo que nunca tinha sido conseguido de forma funcional. E conseguimos mesmo chegar aos utilizadores da versão base do AutoCAD (sem Map nem Civil), que foram também sempre os mais excluídos do SIG. Optou-se por publicar os ortos através de serviços em cache, o que resultou numa óptima performance e numa experiência impressionante para os utilizadores.
No entanto, algumas questões têm suscitado dúvidas e dificuldades: a qualidade das imagens que surgem no AutoCAD têm pouca qualidade quando se utilizam serviços em Cache (principalmente vectores; com ortos não é tão aparente), e não foi ainda possível definir a transformação entre data diferentes (isto é, sobrepor dados WGS84 e Datum73). Também as labels aparecem no AutoCAD mais pequenas do que o esperado, o que obriga a alterar os mxd’s e criar novos serviços no ArcGIS Server especificamente para utilizar em AutoCAD.
Por outro lado, a possibilidade de definir níveis SIG num DWG que depois surgem no ArcMap como Feature Classes, sem necessidade de conversão, é muito apelativa… mais ainda se pensarmos que se podem preparar DWGs vazios com as especificações pretendidas e entregá-los a fornecedores de serviços, projectistas e arquitectos. Estes podem criar a sua informação usando AutoCAD com estes DWGs, trabalhando assim já de acordo com as especificações SIG dos clientes, e sem necessidade de adquirir novo software – bastará usar o plugin gratuito. Mas este é já outro desafio totalmente diferente…


![cad_carto_thumb[1]](/wp-content/uploads/2010/07/cad_carto.png "cad_carto_thumb[1]")
![sig_carto_thumb[1]](/wp-content/uploads/2010/07/sig_carto.png "sig_carto_thumb[1]")







{kind=link}